
HearSight 是一个音视频内容智能分析工具。通过集成先进的语音识别、自然语言处理和大语言模型技术,HearSight 能够自动将视频和音频转化为结构化的文本内容,并在此基础上进行多维度的智能分析和问答交互。无论您是进行学术研究、内容创作还是知识管理,HearSight 都能帮助您深度挖掘音视频内容的价值。
项目地址:https://github.com/li-xiu-qi/HearSight
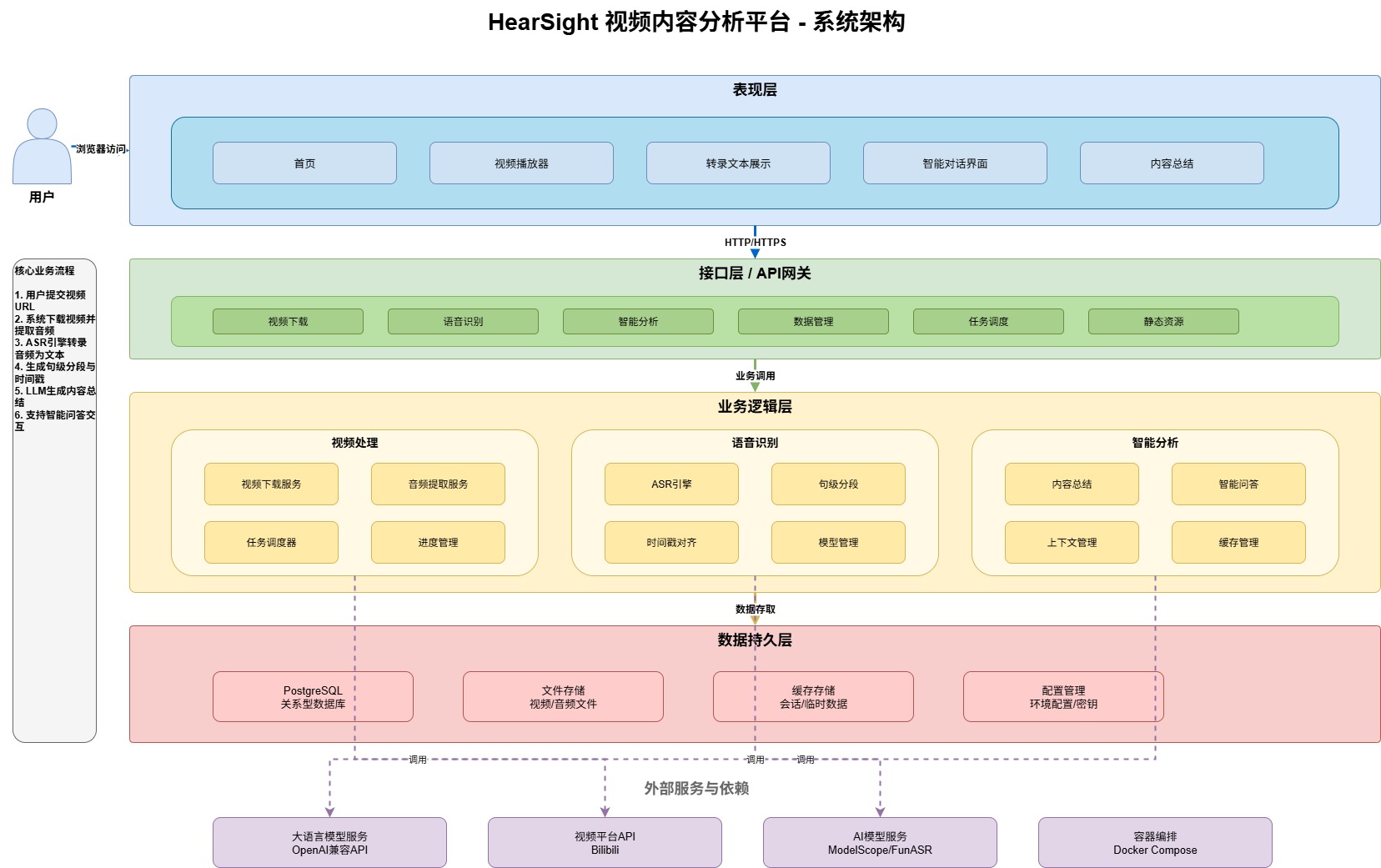
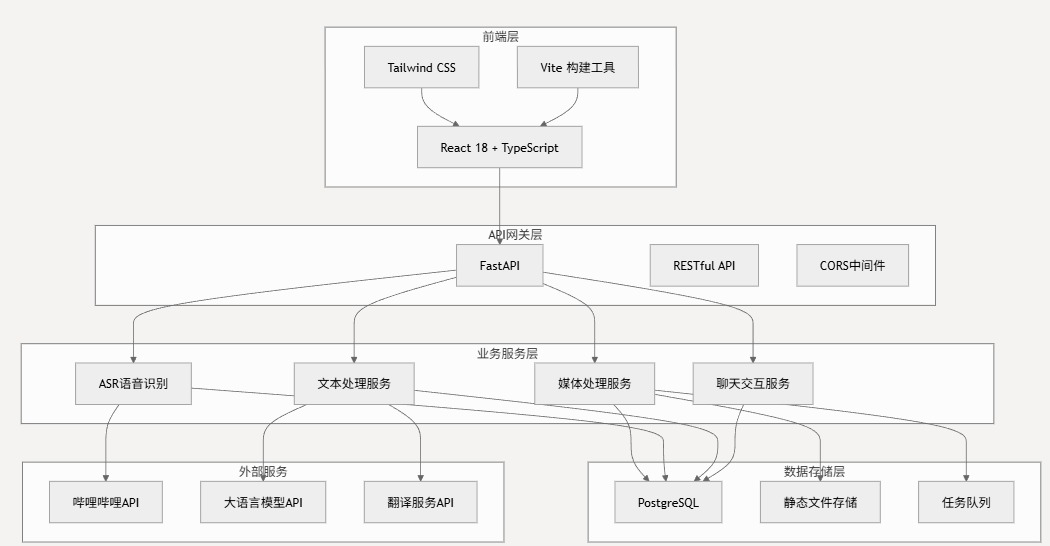
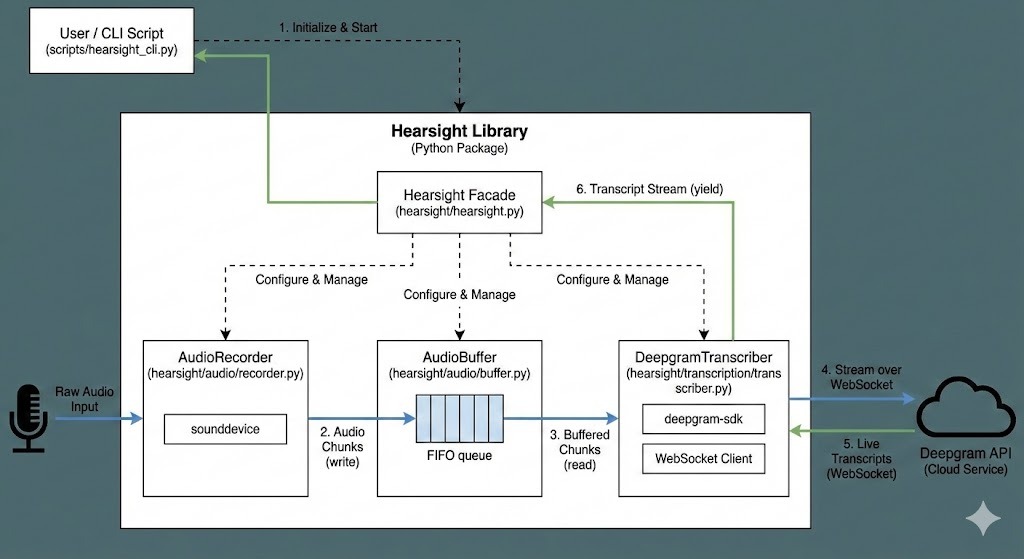
HearSight 采用现代化的微服务架构设计。后端基于 FastAPI 构建高性能 RESTful API,通过 PostgreSQL 实现数据的持久化和查询优化,通过 Celery 构建任务队列处理异步任务;前端采用 React 18 + TypeScript + Tailwind CSS 提供交互流畅的用户界面。整体支持 Docker 容器化部署,开箱即用。
- 📹 集成式媒体导入:直接从哔哩哔哩获取内容,同时支持本地上传视频和音频文件,支持 MP4、AVI、MOV、MKV、MP3、WAV、M4A、AAC 等多种格式
- 🎯 精准语音转写:采用业界领先的 ASR 技术,支持热词识别和实时精确时间戳,自动分句并生成可交互式的文本档案
- 🧠 智能内容分析:基于大语言模型生成段落级和全文级的结构化摘要,支持持久化保存和迭代优化
- 💬 对话式内容理解:支持基于原文的深度问答交互,准确把握关键信息和核心观点,支持单视频和多视频的综合问答与对比分析
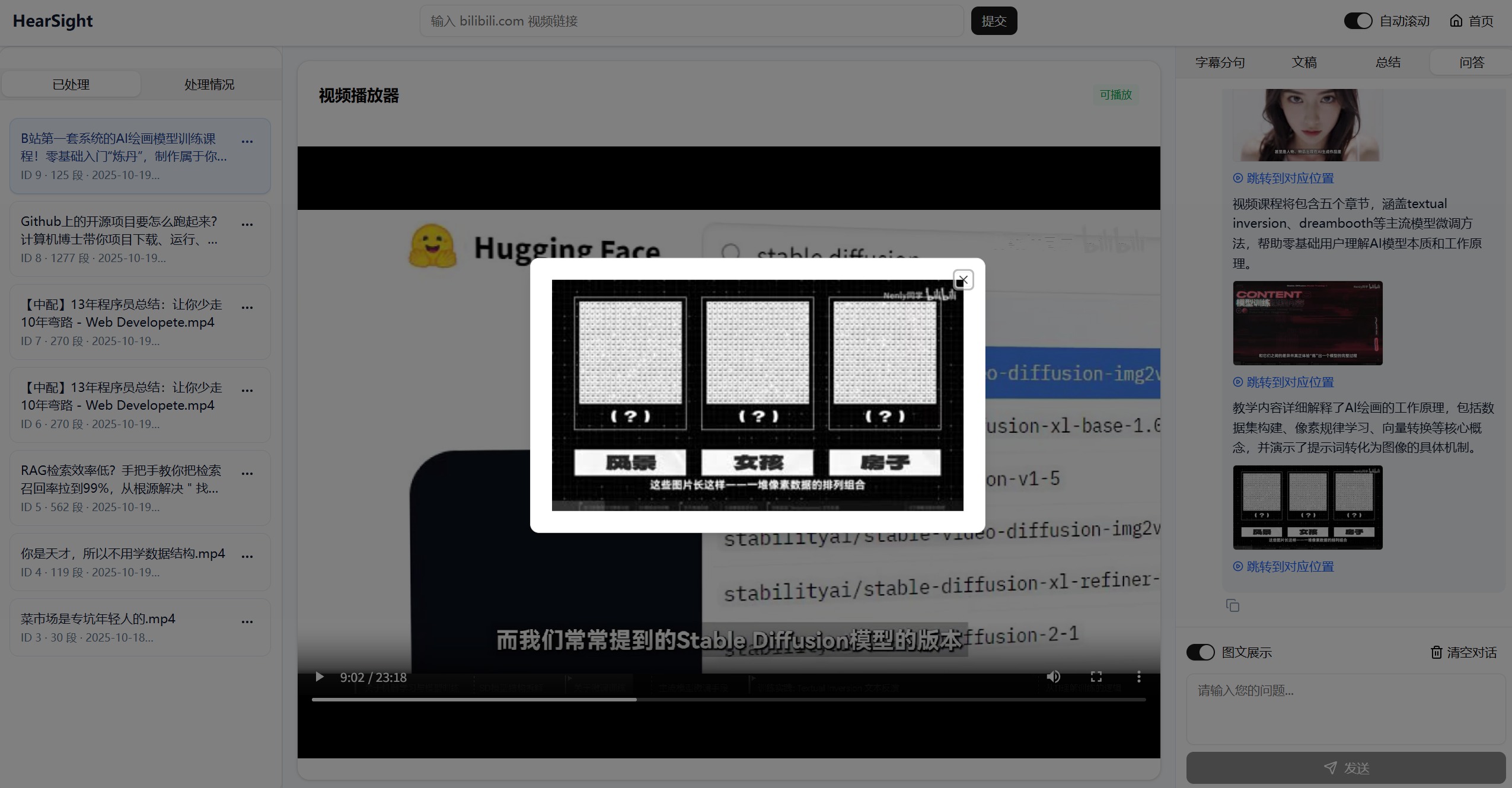
- 🖼️ 多模态信息展示:在问答和总结中融入视频关键帧,实现图文融合的高效表达(仅适用于视频内容)
- 🌐 多语言内容转换:支持自动翻译为多种语言,翻译结果完整保存,便于国际化场景使用
视频播放页展示:
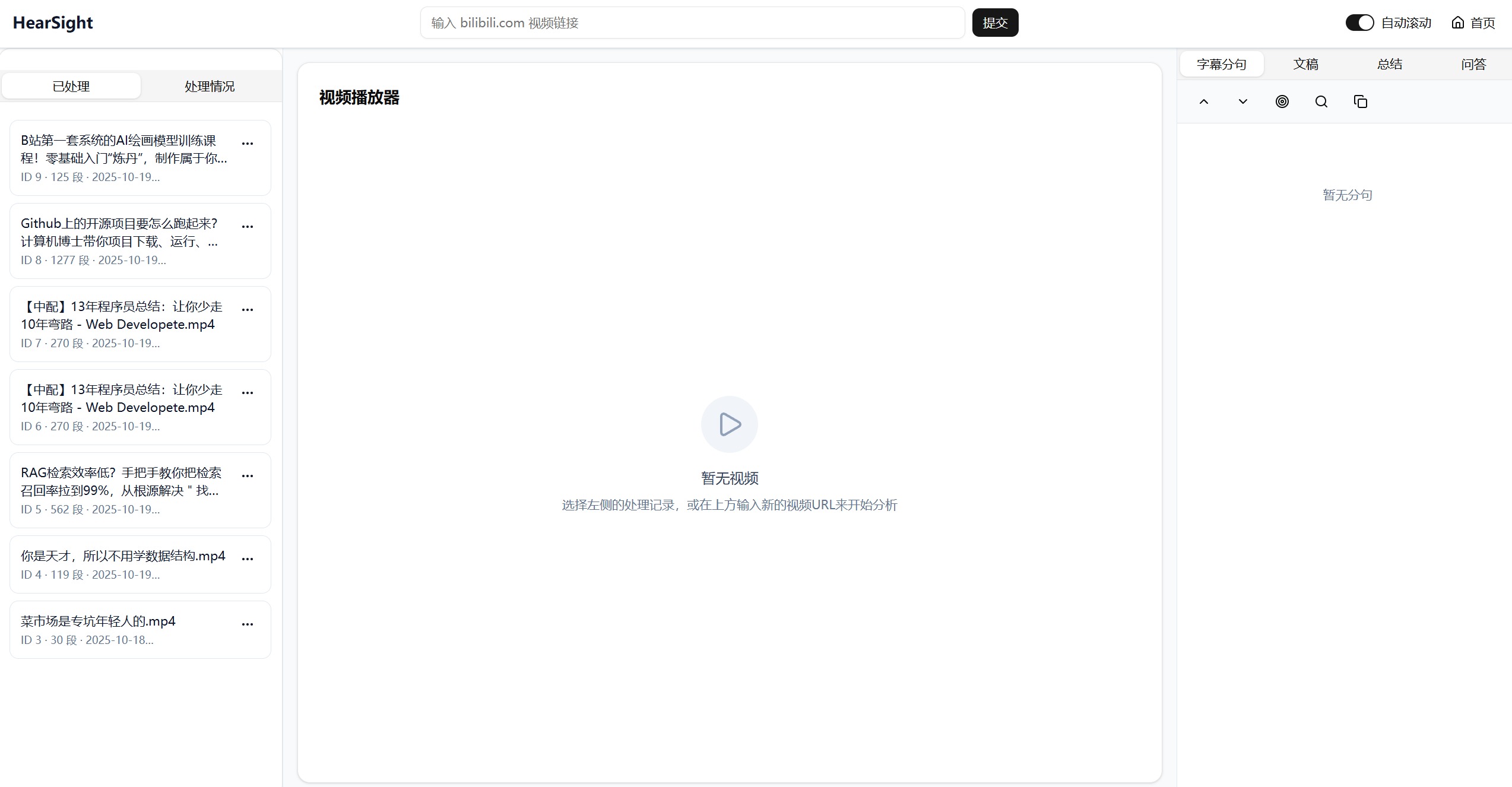
打开一个视频:
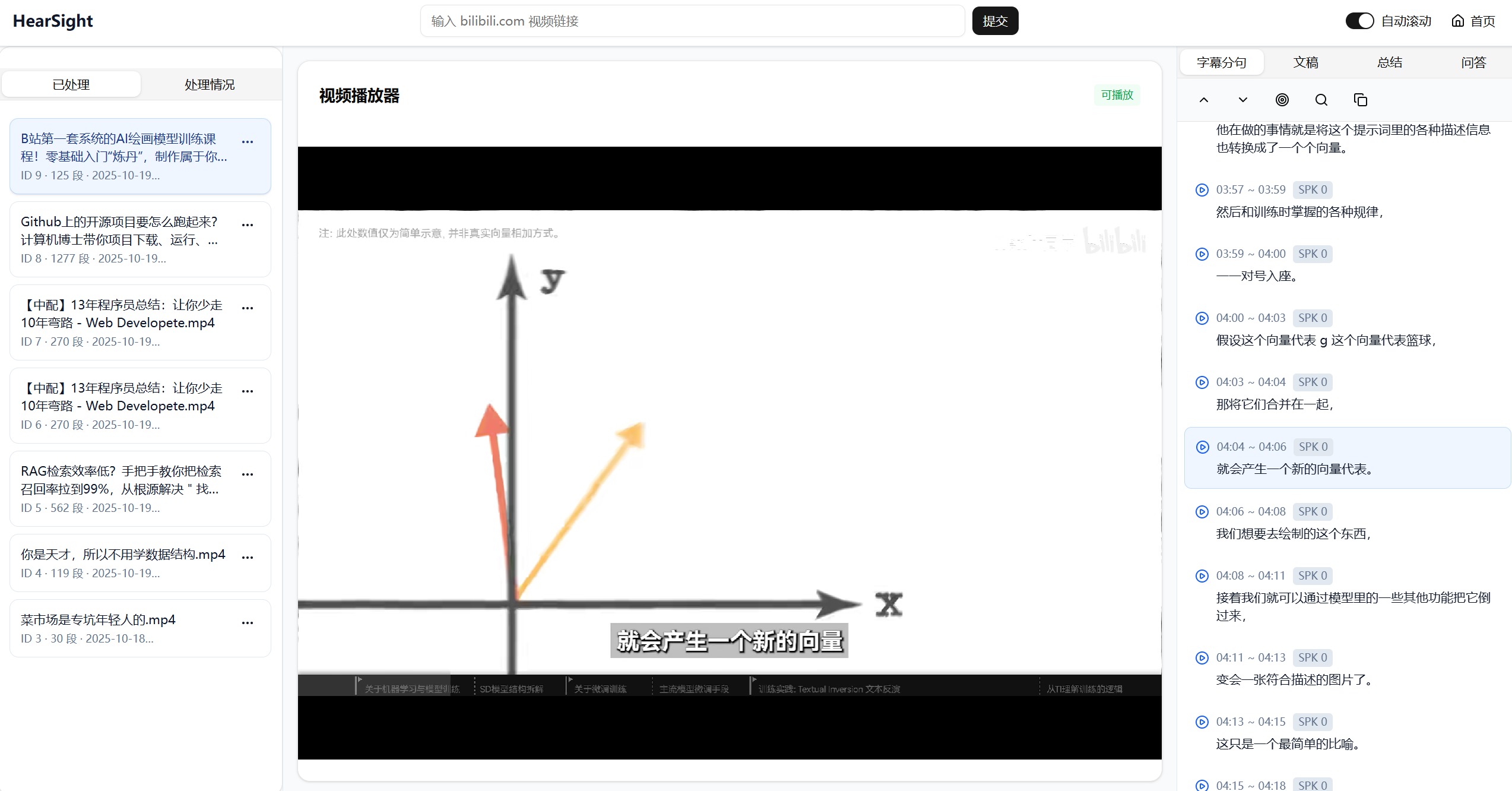
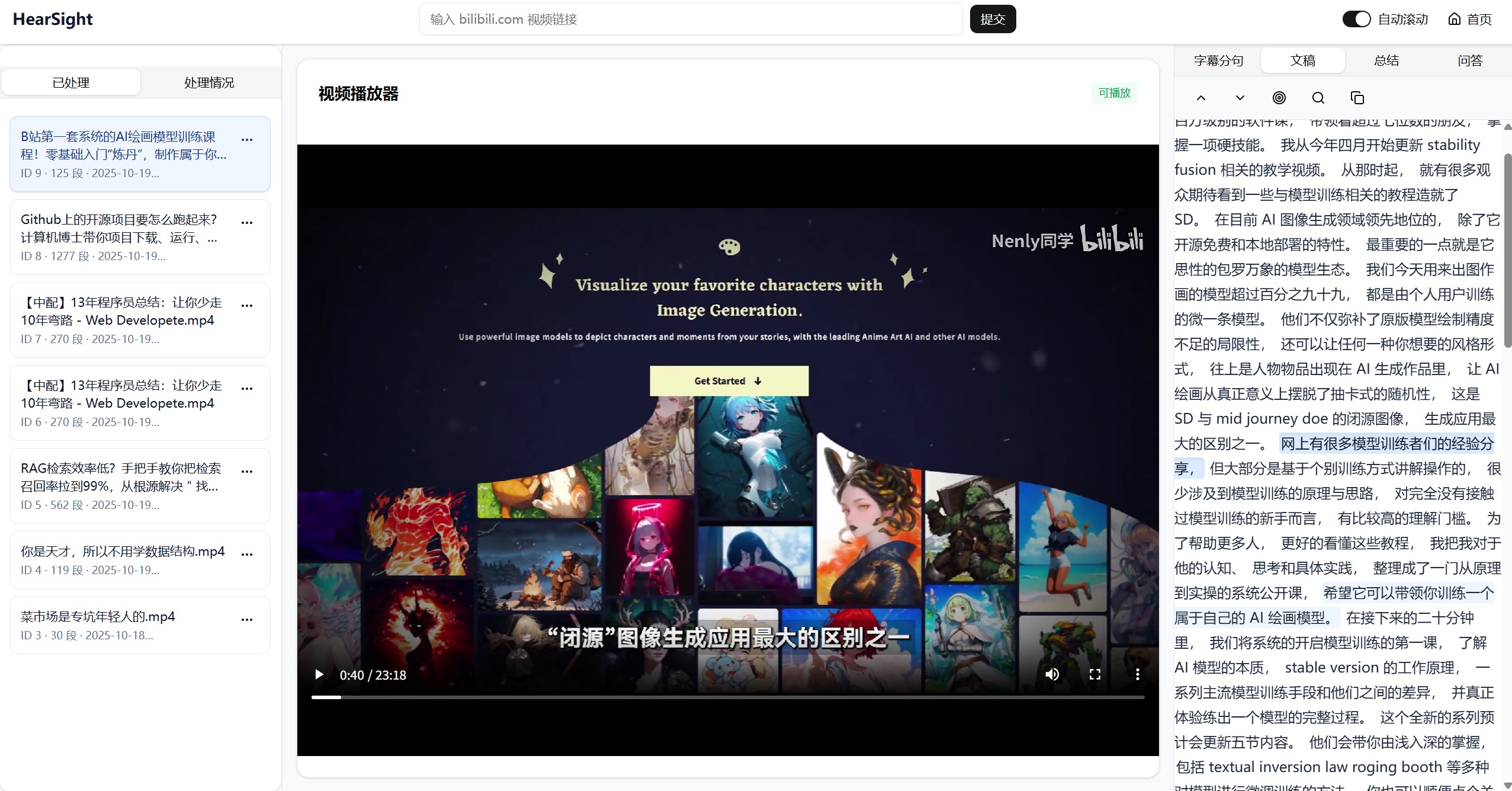
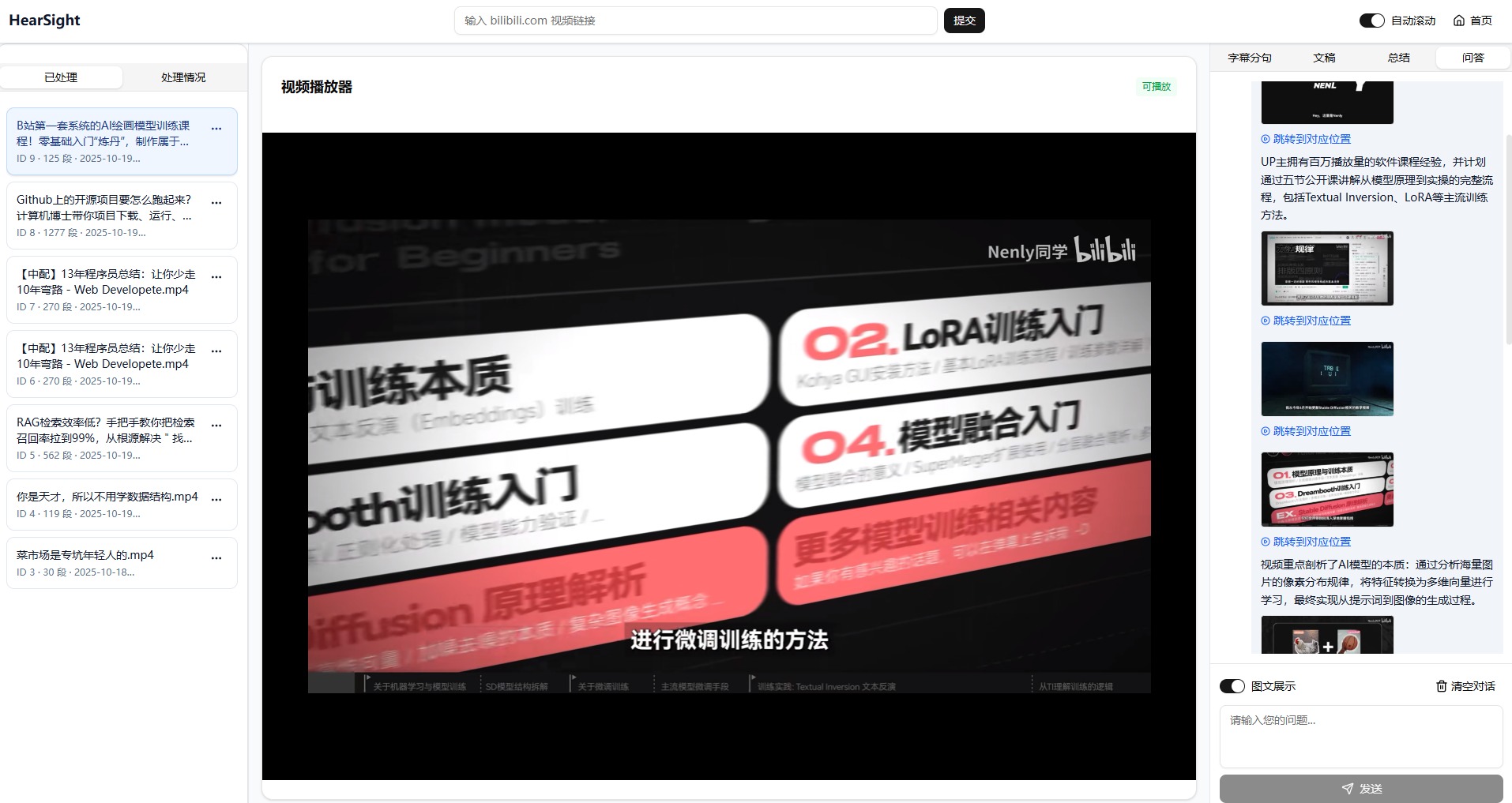
打开视频后的文稿效果展示:
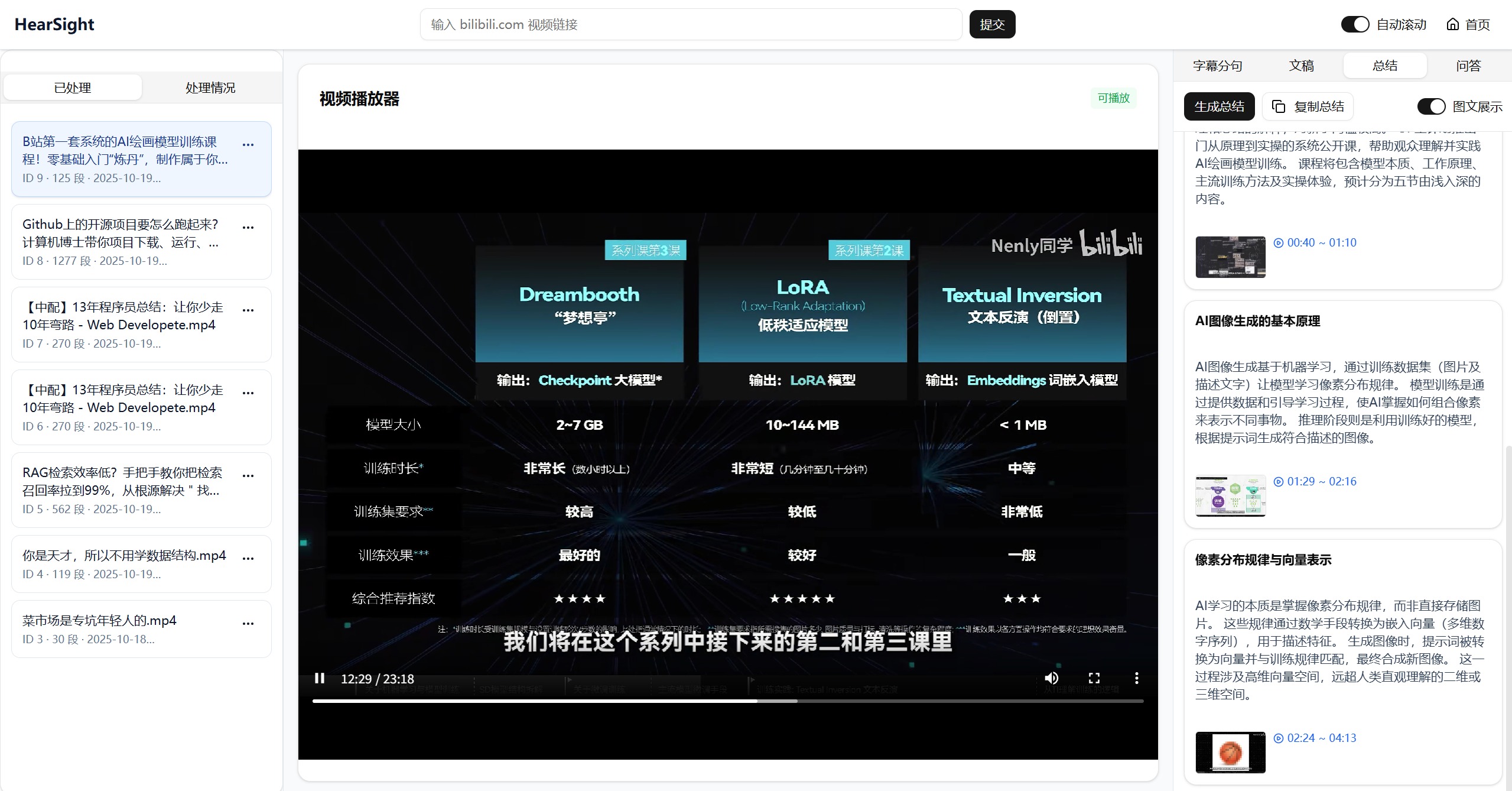
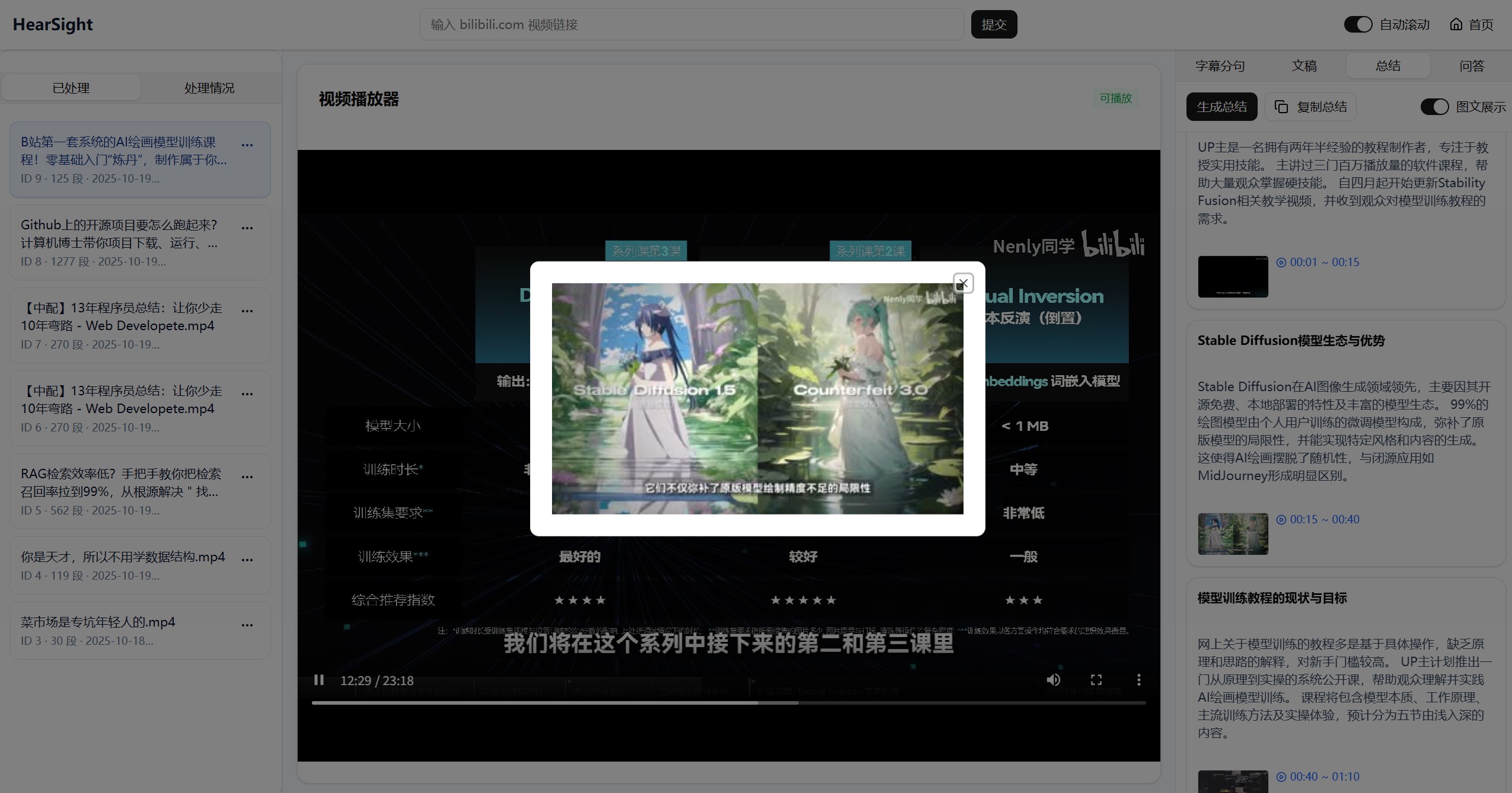
视频总结的展示:
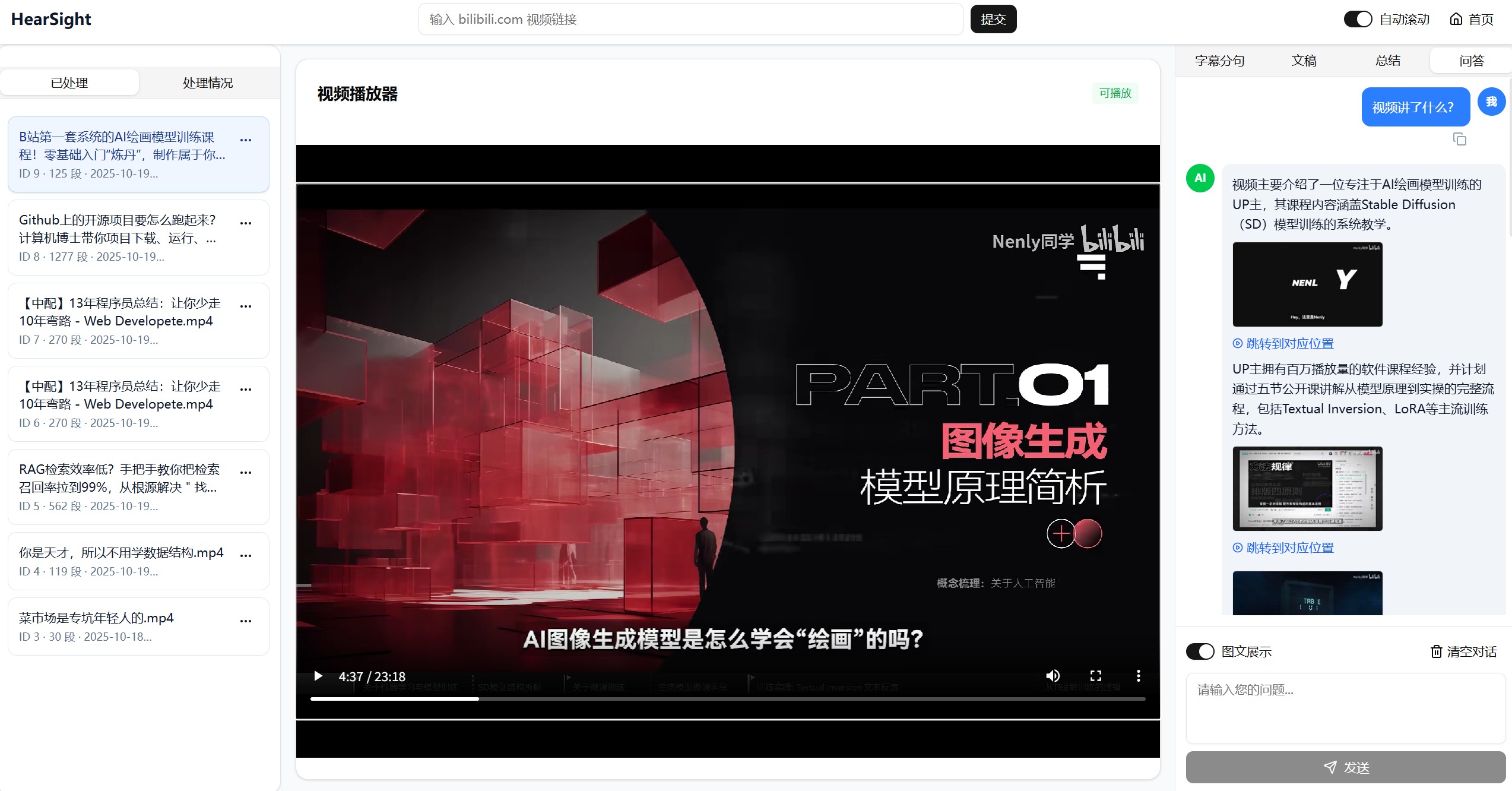
与视频之间的智能对话:
详细的项目结构说明请参考 项目结构。
API 接口文档请参考 API 文档导航。
详细的快速开始指南请参考 快速开始。
学术研究:快速整理讲座音频或视频,建立参考文献档案库。教育培训:自动生成教学讲义和习题解析。内容创作:批量处理视频脚本和文案素材。企业培训:构建结构化的内部知识库与学习平台。客户服务:分析客服录音提取关键问题与解决方案。市场研究:监测竞品视频内容并自动生成分析报告。
集成哔哩哔哩接口可直接获取视频(含登录内容),同时支持本地上传多种格式的音视频文件。系统自动处理文件管理和元数据存储,用户无需手动处理繁琐的文件操作。
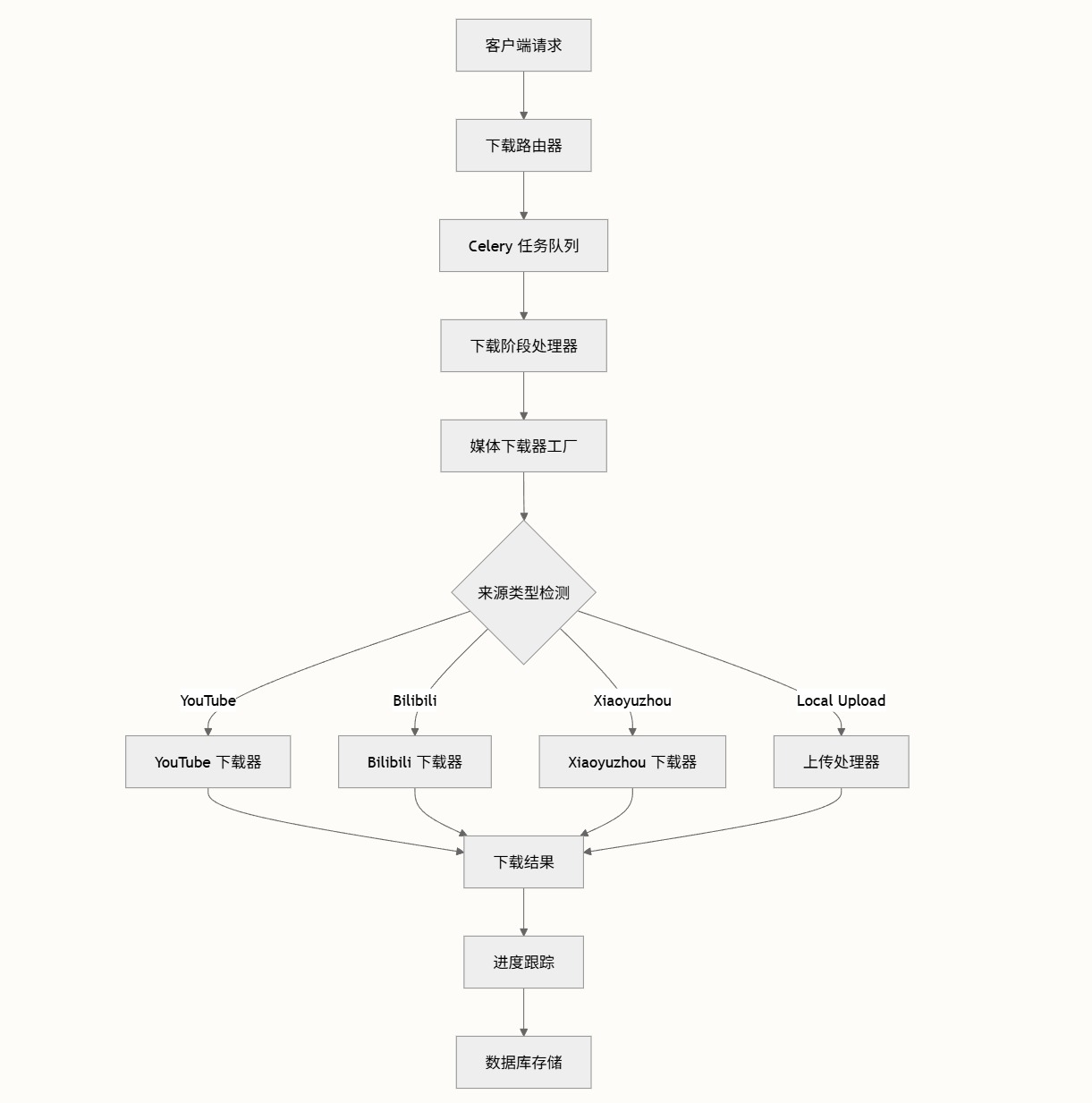

采用行业前沿的 ASR 模型,支持热词识别优化垂直领域准确度。系统自动按句义分割,每个分句精确对应音频时间戳,支持点击即跳转到音视频位置,打破传统文案的线性查看方式。
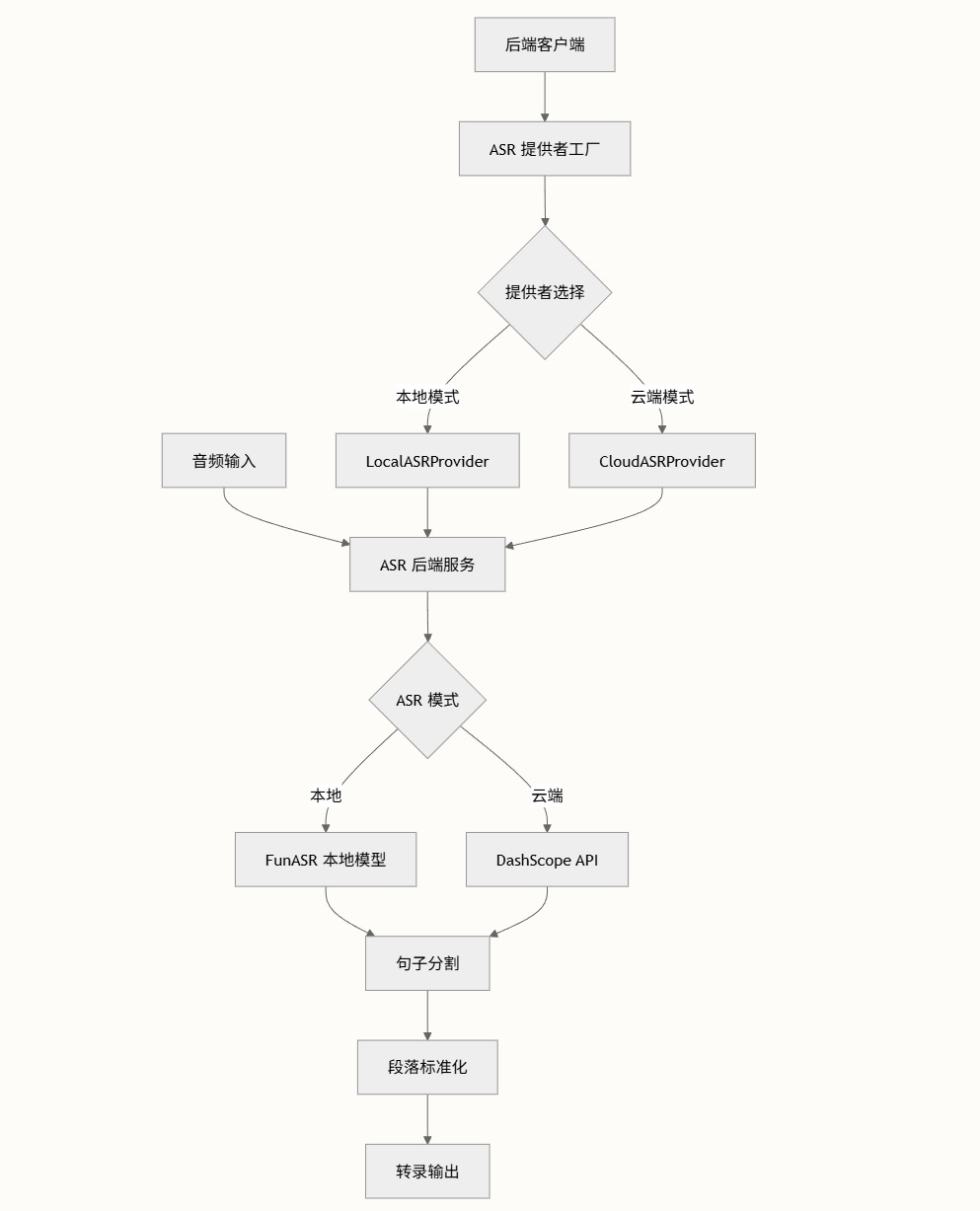
集成大语言模型生成分层级摘要,既能快速获取段落关键信息,也能完整掌握全文内容脉络。摘要自动入库,支持查看历史版本与迭代对比,支持强制重新生成自动覆盖,让内容分析全过程可追溯。
支持一键翻译为多种目标语言,后台异步处理不阻塞主流程,支持实时查看翻译进度。翻译结果完整持久化,多语言内容共存于一个项目中,轻松管理国际化内容。
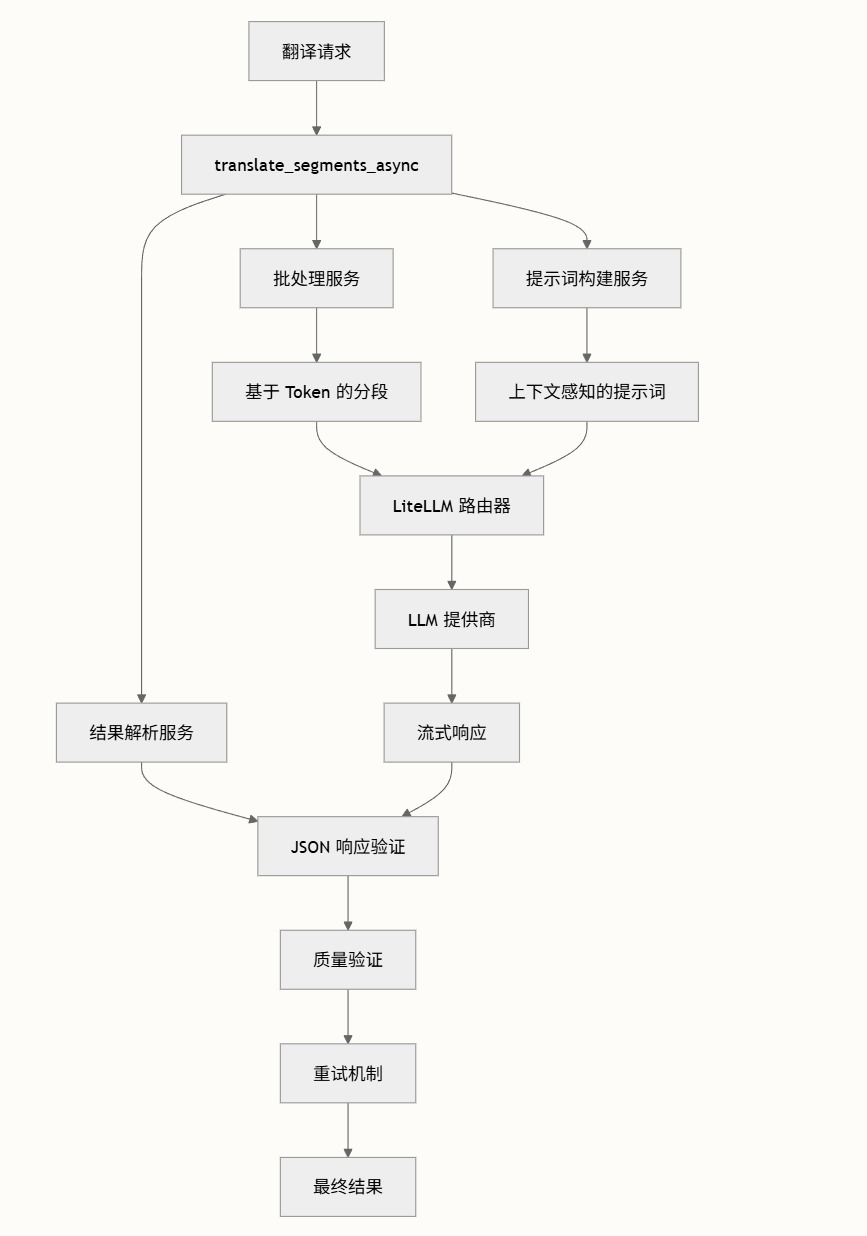
基于原始转写内容进行上下文感知的问答,支持单视频和多视频的综合分析。支持多轮追问与对话历史完整保留,系统能准确把握内容脉络,给出针对性的分析答案。
自动关联视频关键帧到摘要和问答结果中(仅适用于视频内容)。用户可点击查看大图,实现图文结合的直观表达,让复杂概念更容易理解。
HearSight 在实现过程中采用了许多的技术策略,以提升系统的性能和实际效果:
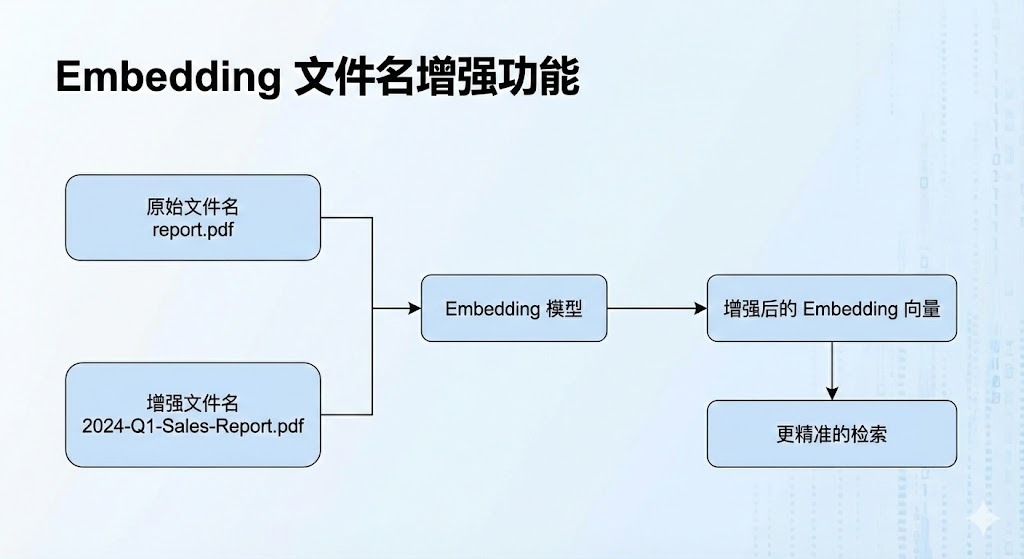
在知识库检索环节,我们实现了 embedding 文件名增强技术。通过在生成文本向量时,将文件名信息与内容文本相结合,形成更丰富的上下文嵌入。具体实现是在 chunk_text 前添加文件名描述,如 "文件名:[filename]\n内容:[text]",从而提升基于文件名提问的检索准确性。该策略有效解决了传统 embedding 仅基于内容而忽略文件名导致的检索不准问题,显著改善了用户查询体验,因为用户基于文件标题提问,很容易错漏相关文件,而给文件名一起进行embedding,会使得整个的效率,召回率平均能提升30%以上。
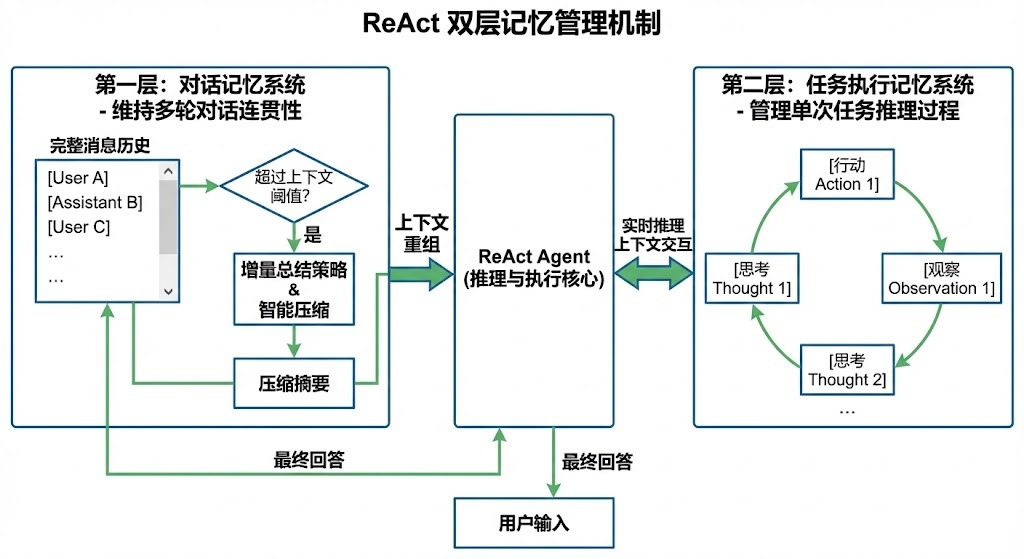
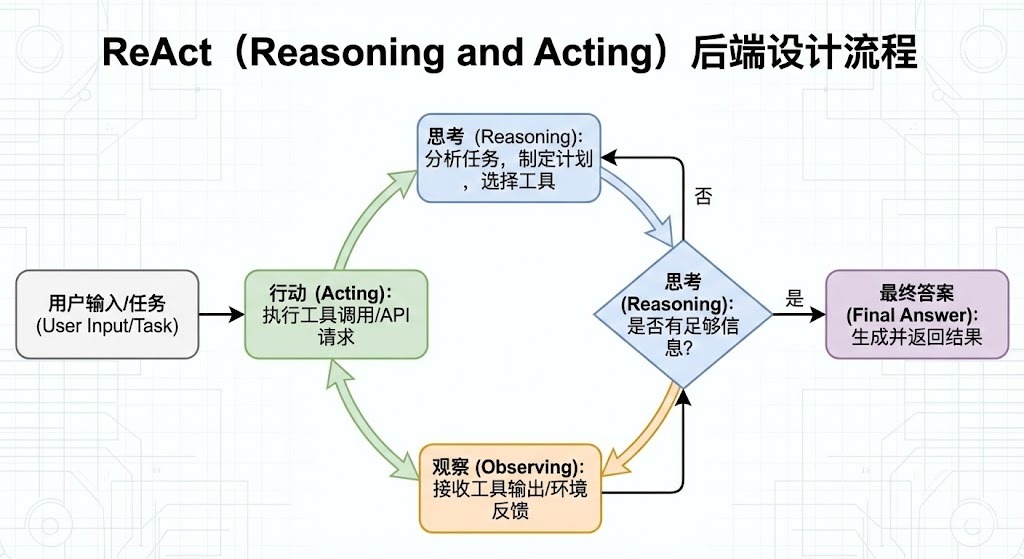
在对话问答系统中,我们采用了先进的 ReAct 记忆管理机制,以应对大语言模型的上下文长度限制。通过智能的记忆压缩和上下文重组,当对话积累的消息超过阈值时,系统自动生成对话摘要,将关键信息压缩存储,同时保留完整的消息历史用于精确重组。这种增量总结策略确保了多轮对话的连贯性,避免了信息丢失,同时控制了上下文长度,提升了问答系统的稳定性和效率。记忆管理分为对话记忆和任务执行记忆两层,前者维持用户与助手的对话连贯性,后者管理单次任务的推理过程,确保了系统的可扩展性和性能优化。
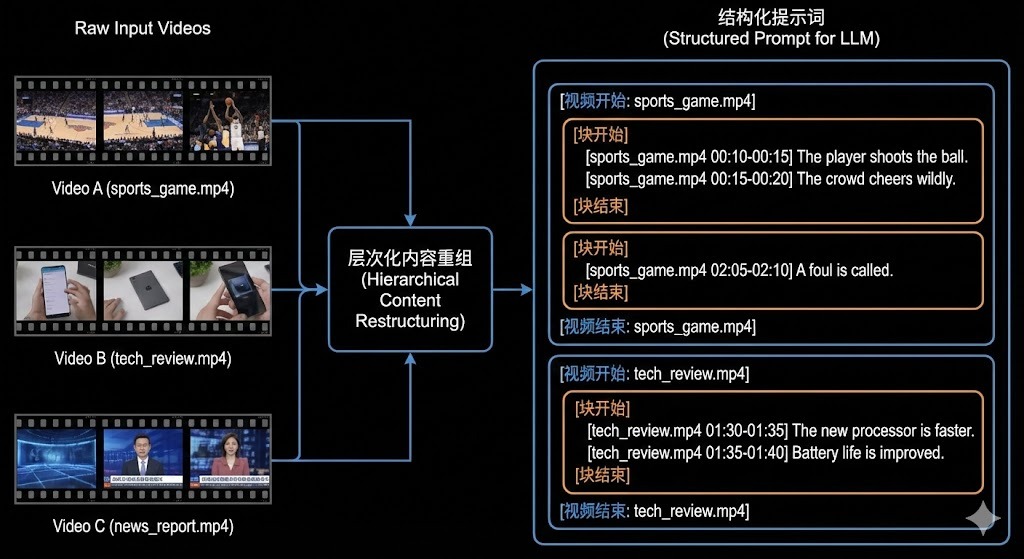
在多视频问答场景中,我们设计了层次化的检索内容重组结构,以确保不同视频和内容块有清晰的分界线。该结构采用嵌套标签系统:[视频开始/结束] 包围整个视频内容,[块开始/结束] 分隔连续的内容片段,每个句子附带精确的时间戳 [filename start-end]。这种设计避免了多视频内容混淆的问题,使大语言模型能够准确识别和引用特定视频段落,提升问答的精确性和可追溯性,同时保持提示词的结构化和可读性。
HearSight 是一个开源项目,我们欢迎来自社区的改进和贡献。无论是功能增强、bug 修复还是文档改进,都可以通过提交 Pull Request 的方式参与。如果有好的想法或发现问题,也可以直接提交 Issue。
本项目采用 Apache-2.0 License 开源许可证。详见 LICENSE 文件。