Created articles.py with citation check and spell check. #20
Conversation
A function to check out citations of a website (article in general).
Added a missing import.
Update my fork to the main repo
Articles.py for processing the article.
Added the dictionary to refer to.
|
I'll update my pull request with the latest headline.py when the other current pull request gets added. |
|
|
||
| #For prototyping only - | ||
| if(__name__=="__main__"): | ||
| article = newspaper.Article("http://www.bbc.com/future/story/20190801-tomorrows-gods-what-is-the-future-of-religion") |
There was a problem hiding this comment.
Lets keep the article initiation in the actual program. This is beneficial since the input in the other function also is an url.
There was a problem hiding this comment.
Yes, agreed. I was thinking we can have a main.py in which we make an article object and then call headline.py, article.py, and others, passing the article as an object.
The if(name=="main") is only for trial or if someone runs article.py directly. I should probably replace it with an error message.
There was a problem hiding this comment.
Yes once we are done creating all the required modules, we will surely have to create a main.py. for now we will stick with name==main in every module
| article.download() | ||
| article.parse() | ||
| ArtCon = article_content(article) #Create object. This opens init and tokenizes article. | ||
| print("Number of citiations, ", ArtCon.citation_check()) #Citation check |
There was a problem hiding this comment.
I would add this to a main function in the class. Simply to keep the actions inside of the class.
There was a problem hiding this comment.
I'm assuming the downloaded and parsed article will be available because of prior processing in headline, so we shouldn't have to do this inside article again, right?
Something like
Create article object
Pass to headline class, extract all the headline stuff
Pass to article class, extract all the article stuff
I'm only using the article.download() and article.parse() here because article and headline aren't linked yet with a main function.
There was a problem hiding this comment.
Yeah, we could do that, but it would be a lot faster if we could do those, and more, functions in parallel. Therefore, it would be better to create the article object separately to prevent conflicts.
There was a problem hiding this comment.
we might also need init file ? so we can do all our initialisation ?
There was a problem hiding this comment.
Not necessary if we just use init function
|
|
||
| def spell_check(self): | ||
| for word in self.tokenized_words: #For every word in article | ||
| if word[0].isupper()==False: #Ignore if first letter is uppercase, else |
There was a problem hiding this comment.
Only necessary when the word is not the first word in a sentence.
There was a problem hiding this comment.
True! I will try to fix this using punctuations in tokenized_words.
There was a problem hiding this comment.
Do you have any suggestions regarding the problem that might arise with sentences starting with proper nouns?
Like
John went to the school.
Here, John is not a misspelling, but if we don't ignore the first word in the sentence, it will be counted as a misspell.
Stoodunts go to the school
Here Stoodunts is a misspelling but if we ignore the first word in the sentence, it will be ignored and we won't be able to count it.
I thought of something that counts the misspelling with the frequency of it. If it occurs many times, then it probably is a proper noun, but I'm not certain as to how to go about deciding what threshold it will be. It has to be dependent on the article text length I'm guessing, but haven't thought of much more.
There was a problem hiding this comment.
nltk.corpus.names.words would be a viable option
| #Whenever a class object is made, the article is tokenized and the dictionary file is opened as a set. | ||
| self.tokenized_words = nltk.word_tokenize(article_object.text) | ||
| self.article_object = article_object | ||
| with open('words_alpha.txt') as word_file: |
There was a problem hiding this comment.
Why is your dictionary not a module input? That would be significantly faster and easier.
There was a problem hiding this comment.
Can you elaborate? I can't find anything on module inputs online.
There was a problem hiding this comment.
For example; https://pypi.org/project/PyDictionary/
Using mapping instead of iterating is significantly faster.
There was a problem hiding this comment.
Well, we are only going to check whether the word exists in the file or not...don't really want to extract any other definition.
Sets are quite fast at determining whether an element in present in them or not because sets can only have unique values (it was the fastest method that I tried by quite a long margin). I'll have to compare sets vs mapping after I read up a little bit more on mapping. Still quite unsure about what it perfectly means.
I do believe just making the set once is enough though, so you like suggest, maybe it can be done in a different file and then imported when necessary.
There was a problem hiding this comment.
Why would you want it to exist in a file? It needs to be in the dictionary since it needs to be an actual word. The fastest way to check if a word is in the dictionary is using a dictionary module.
|
|
||
| return self.number_unique_citations | ||
|
|
||
| def spell_check(self): |
There was a problem hiding this comment.
This function would be quicker if it was ordered like this;
- Filtering actions on article main text.
- Iterate over the rest of the words.
| self.not_citations = ("facebook.com", "twitter.com", "#", "mailto", "plus.google", "advertising", "advertisement", "ad.", "/", "whatsapp", "quora", "nav.", "instagram") | ||
|
|
||
| self.article_html = self.article_object.html | ||
| http = [self.article_object.url] + re.findall(r'href="[^\"]+', self.article_html) #Regex code for finding links, eg href="http://www.bbc.com" returns http://www.bbc.com. |
There was a problem hiding this comment.
Soup would be faster at this.
But Im quite sure you could get citations and urls from the newspaper module.
There was a problem hiding this comment.
Trying to keep imported libraries to minimum.
Soup would easily give the citations with
for link in soup.find_all('a'):
print(link.get('href'))
But it would pull stuff like "https://github.com/Learning-Python-Team/UnTruth/pull/20" but I consider each website source linked as only one citation, so want "github", so regex would be needed anyway to detect the / (and remove everything ahead) and only retain "github.com".
I would have to use soup.findAll(re.compile("REGEX EXPRESSION")) at which point, I think directly using regex is probably better. I'll compare the timings and see later on when I have time.
But Im quite sure you could get citations and urls from the newspaper module.
I could not find this in newspaper quickstart documentation.
There was a problem hiding this comment.
Yeah, I did some googling, but I think I was wrong regarding newspaper returning links. However, newspaper uses the requests library. With this library, you can easily get all links quicker than bs4.
A quick example would be;
session.get(URL).html.absolute_links With the list that this returns, you could use the urlparse library (or plain regex) to categorize the links. I'd say, give it a quick test to see which is faster and go for the fastest option.
There was a problem hiding this comment.
@mandjevant how do one check if one is faster over the other ?
There was a problem hiding this comment.
On a CPU, for an already parsed article, the regex method is faster.
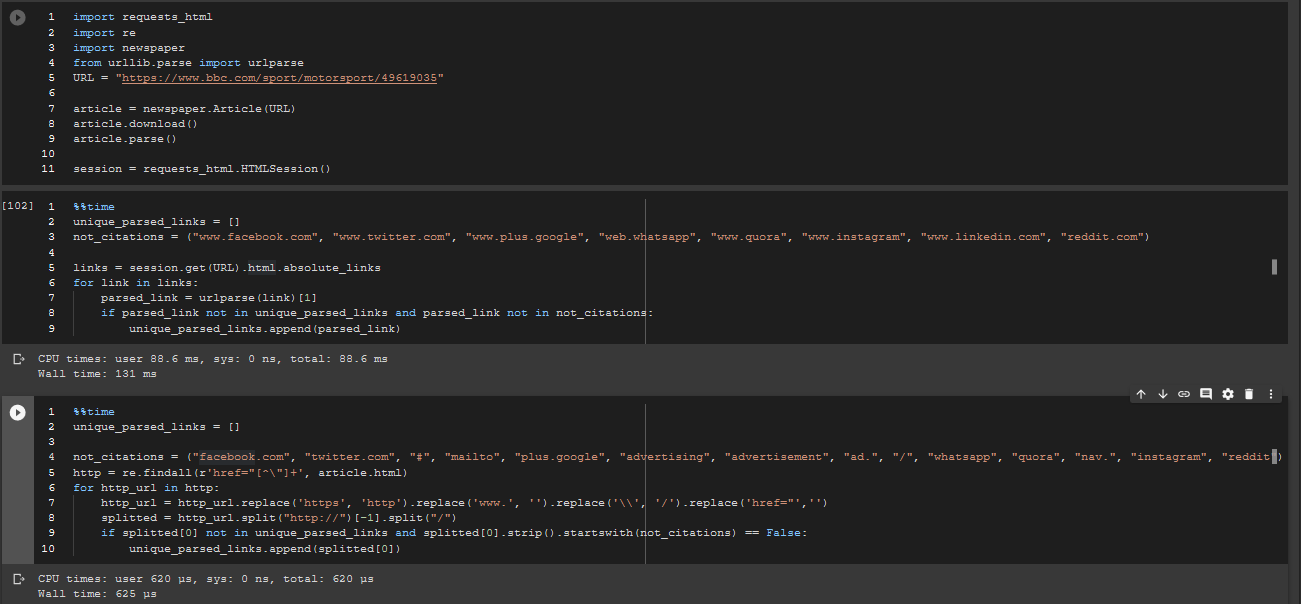 by a order of 1000 or so (microseconds vs milliseconds).
by a order of 1000 or so (microseconds vs milliseconds).
But we'll need the parsed article anyway for other functions and the whole article analysis so if you consider loading the requests_html within the cell, it's even worse (although the more consuming part is downloading the url over and over.)
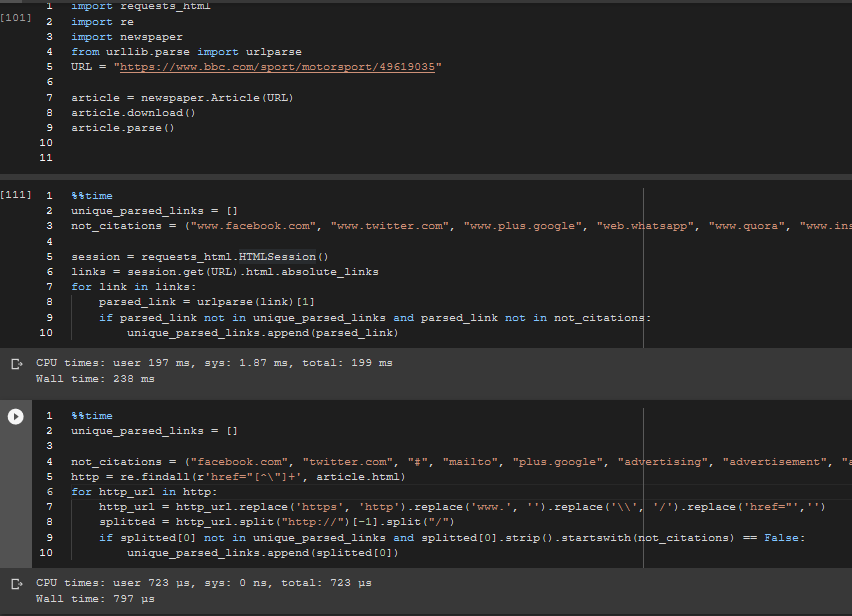
Timed over a 100 loops - Still quite better (even with the session made outside the block, downloaded outside and links extracted outside)
EDIT : I realized I put the wrong image here earlier (that had the block going through the URL over and over). Here is a comparison of preloaded sessions + preloaded links for HTML_requests vs preloaded article parsed and downloaded, which is an unfair comparison, because the links are already loaded in html_requests, (the list only has few links) but the regex method has to go through the entire HTML.
Done over a 100 loops.
Still faster by about 200 microseconds or so per cycle.

absolute_links is the main culprit behind the slowness, although they do find the links slightly better than my method. I don't think the results should be so different once the entire list of not_citations is up and only body part is extracted.

Colab notebook on which I did the testing - https://colab.research.google.com/drive/1o94PRcDUXiARfpt3fYeMiCw_OVm3J94h
There was a problem hiding this comment.
As for further improvement, I'm going to count citations that are only within the tags, because outside that it's probably ads and navigation and footer. What do you think @mandjevant ? Is that wise to do?
There was a problem hiding this comment.
how do one check if one is faster over the other ?
You can use time or timeit. https://docs.python.org/3/library/timeit.html
If you are familiar with Jupyter notebooks, they have a shortcut for it.
%time for one line time.
%timeit for one line time, iterated over many loops (like I did for 100 in above image) and finding the best 3 of them (usually)
%%time for the entire cell time.
%%timeit for the entire cell time, iterated over many loops, and finding the best 3 of them (usually).
| @@ -0,0 +1,60 @@ | |||
| import nltk | |||
| import newspaper | |||
There was a problem hiding this comment.
importing newspaper takes significant amount of time. Do you think its possible we import only required module from it like from newspaper import Article as article This will only import the article module as that's all we are using from it. If yes, we need to find a way to pass url to it.
There was a problem hiding this comment.
Very good idea! I'll do that.
Although since our article object was named 'article', I think simply importing from newspaper import Article would be better.
There was a problem hiding this comment.
how do we pass the url of the article now ?
| self.not_citations = ("facebook.com", "twitter.com", "#", "mailto", "plus.google", "advertising", "advertisement", "ad.", "/", "whatsapp", "quora", "nav.", "instagram") | ||
|
|
||
| self.article_html = self.article_object.html | ||
| http = [self.article_object.url] + re.findall(r'href="[^\"]+', self.article_html) #Regex code for finding links, eg href="http://www.bbc.com" returns http://www.bbc.com. |
There was a problem hiding this comment.
@mphirke can you explain the line 21,22.
There was a problem hiding this comment.
In line 21, we store the HTML text of the article in self.article_html.
For line 22...
Links in HTML are given like
<a href="mylinkhere"
So using regular expressions(Regex), we find out all the patterns that fit into the format href="[^\"]+
To explain this format, I will have to explain a little about regex. 'href="' means that whatever we are finding should contain that. So suppose we have <a href="mylinkhere", the part href= from it will be found (for now).
Later, [^\"] means any character BUT ", because " will end the href tag. The + is to show that the last condition [^\"] i.e. any character BUT " is allowed will be repeated until a " is found.
Actually, for regex, you only need [^] instead of [^\"], but it's a " so need to escape it in Python when using "" "" brackets.
Anyway, a picture = 1000 words, so you can check that it has extracted the URLS -

There was a problem hiding this comment.
You can see it in action here -
https://regex101.com/r/Jeg4Qd/1
|
|
||
| def spell_check(self): | ||
| for word in self.tokenized_words: #For every word in article | ||
| if word[0].isupper()==False: #Ignore if first letter is uppercase, else |
There was a problem hiding this comment.
there is no 'else' or 'elif' in the loop what happens when none of the 'if' condition matches. does the program simply return misspells ?
There was a problem hiding this comment.
Then misspells is returned as 0 (as initialized as 0 in init).
| word_lowercase = word.lower() #Convert to lowercase | ||
| asciis = [ord(char) for char in word_lowercase] #Find out ASCIIs of word | ||
|
|
||
| if all(ascii_key >= 97 and ascii_key <= 122 for ascii_key in asciis)==True: #Only accept is ASCII's are alphabetical. Numbers cannot be misspelled. |
There was a problem hiding this comment.
I think this is indented one too many time. Can you please confirm ?
There was a problem hiding this comment.
Do you follow 2 space as tab spacing in Python? I'm not sure because Colab sometimes uses 2 spaces but sometimes uses 4 spaces and it gets a little confusing for me too.
If you're talking about it code wise, then no. It's working as indented. The word should only be checked further if the first letter is not uppercase.
I'm working on changing it so that it also checks whether the word is at the beginning of the sentence or not.
Also added the dictionary.
Modification was done to the latest stable version, so headlines is not updated to the riseandshine0's latest pull request.