{kind=link}
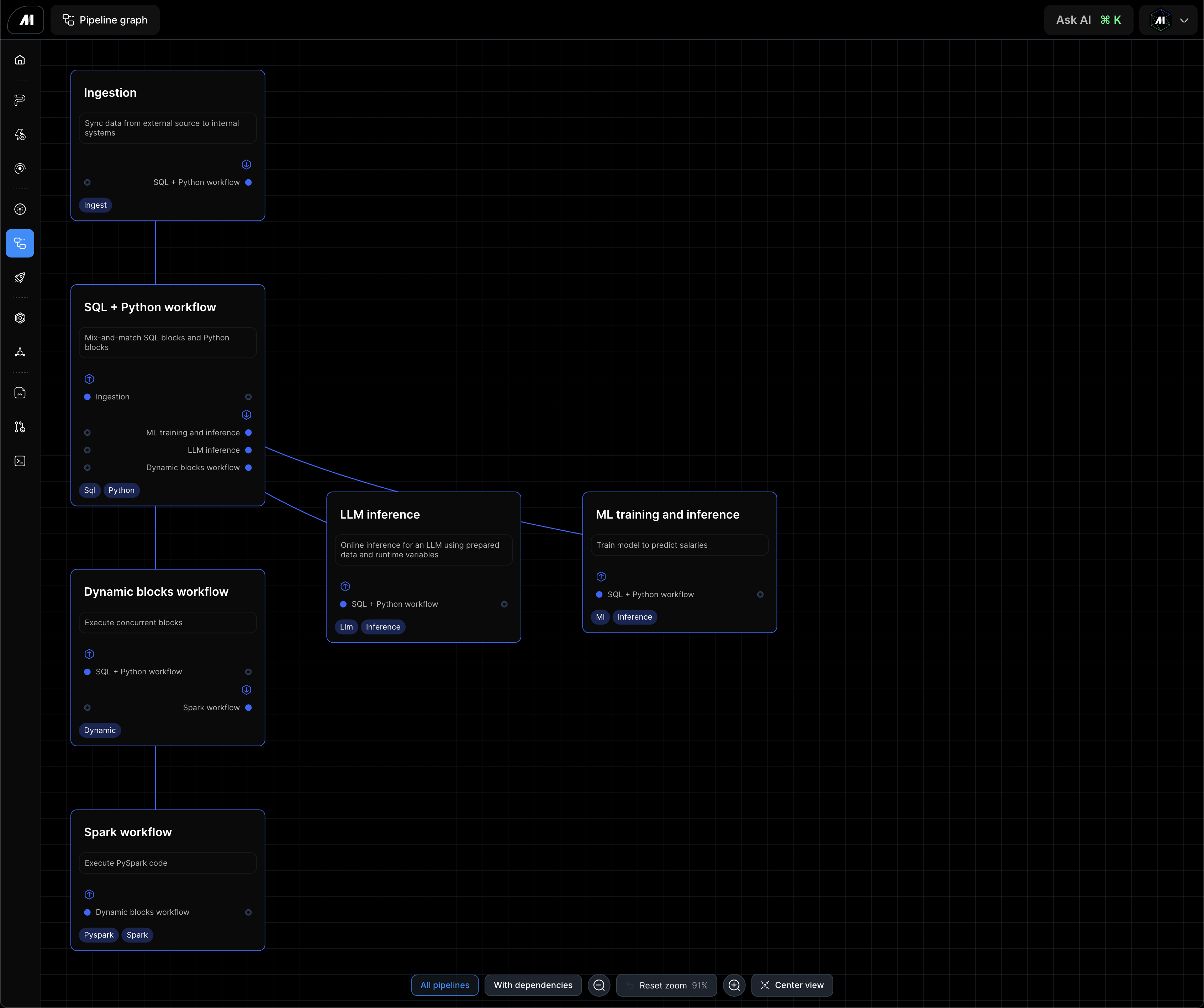
Schedule: every 15 minutes
- Load data from API
- Transform by rounding the employeeCount column
- Export data to DuckDB
Schedule: Hourly after waiting for ingestion to complete
- Sensor: wait until ingestion workflow completes
- Load titanic dataset from CSV
- Load ingested data from DuckDB using SQL block and join with the data from the Python block that loads from the CSV
- Trigger dynamic block workflow: this workflow passes in runtime variables when it triggers the dynamic block workflow; that value is available throughout the dynamic block workflow via the keyword arguments (e.g. kwargs)
- Trigger ML training workflow
Triggered by SQL + Python workflow
- Dynamic block uses the variable passed from the SQL + Python workflow (e.g. count), then spawn N child blocks where N is the count variable value divided by 1000.
- Each child block will received 1 item from the list produced by the 1st block; for example, if the 1st block returns a list of 10 items, the downstream child block will be spawned 10 times
- AI block: using the data passed from the upstream block, pass that data into an LLM and prompt the model. 1. After fanning out N times, reduce all the outputs into a single list and pass that data to the next block
- Trigger Spark workflow: use the collected list of items from the AI blocks and trigger the Spark workflow and pass that data as a runtime variable
Triggered by Dynamic block workflow
- Generate sample salary data and write to Spark
- Load fun facts from runtime variables via the "fun_facts" keyword argument that’s passed to the workflow by the Dynamic block workflow
- Transform: combine the data from the 1st two blocks
Triggered by SQL + Python workflow
-
Global Data Product (this single data product can be re-used across workflows as a single canonical dataset that only recomputes if it’s stale e.g. after 1 day seconds. If the dataset is not stale, the most recent computed data will be used): Load core user data from
-
Transform: prepare the core user data for training
-
Train ML model: train XGBoost model to predict "survived" column
-
Online inference block to be used to predict whether a person survives based on a set of features
Example API request:
curl -X POST https://cluster.mage.ai/mageai-0-demo/api/runs \ --header 'Content-Type: application/json' \ --header 'Authorization: Bearer XXXXXXXXXXXX' \ --data ' { "run": { "pipeline_uuid": "ml_training_and_inference", "block_uuid": "online_inference", "variables": { "pclass": "3", "_name": "Kim", "sex": "female", "age": "21", "sibsp": "0", "parch": "0", "ticket": "315037", "fare": "100", "cabin": "D21", "embarked": "S" } } }' -
AI block: given the person’s attributes and survival prediction, get an explanation as to why that prediction was made
API triggered endpoint
-
Global data product: use the canonical core users data
-
Transform: de-dupe
-
AI block: analyze and create a decision making framework for deciding if someone survives based on any information they provide
-
AI block: predict and explain why someone would survive a boat crash based on any runtime variable data they provide about a person
Example API request:
curl -X POST https://cluster.mage.ai/mageai-0-demo/api/runs \ --header 'Content-Type: application/json' \ --header 'Authorization: Bearer XXXXXXXXXXXX' \ --data ' { "run": { "pipeline_uuid": "llm_inference", "block_uuid": "will_i_survive", "variables": { "about_me": { "bio": "I am a 21-year-old male from Japan and I have OP cheat-magic. I am a student and I love to travel." } } } }'