This is the repository for TMLR paper Data Pruning Can Do More: A Comprehensive Data Pruning Approach for Object Re-identification
ReID datasets generally present two issues:
- Less informative samples
- Noisy labels and outlier samples
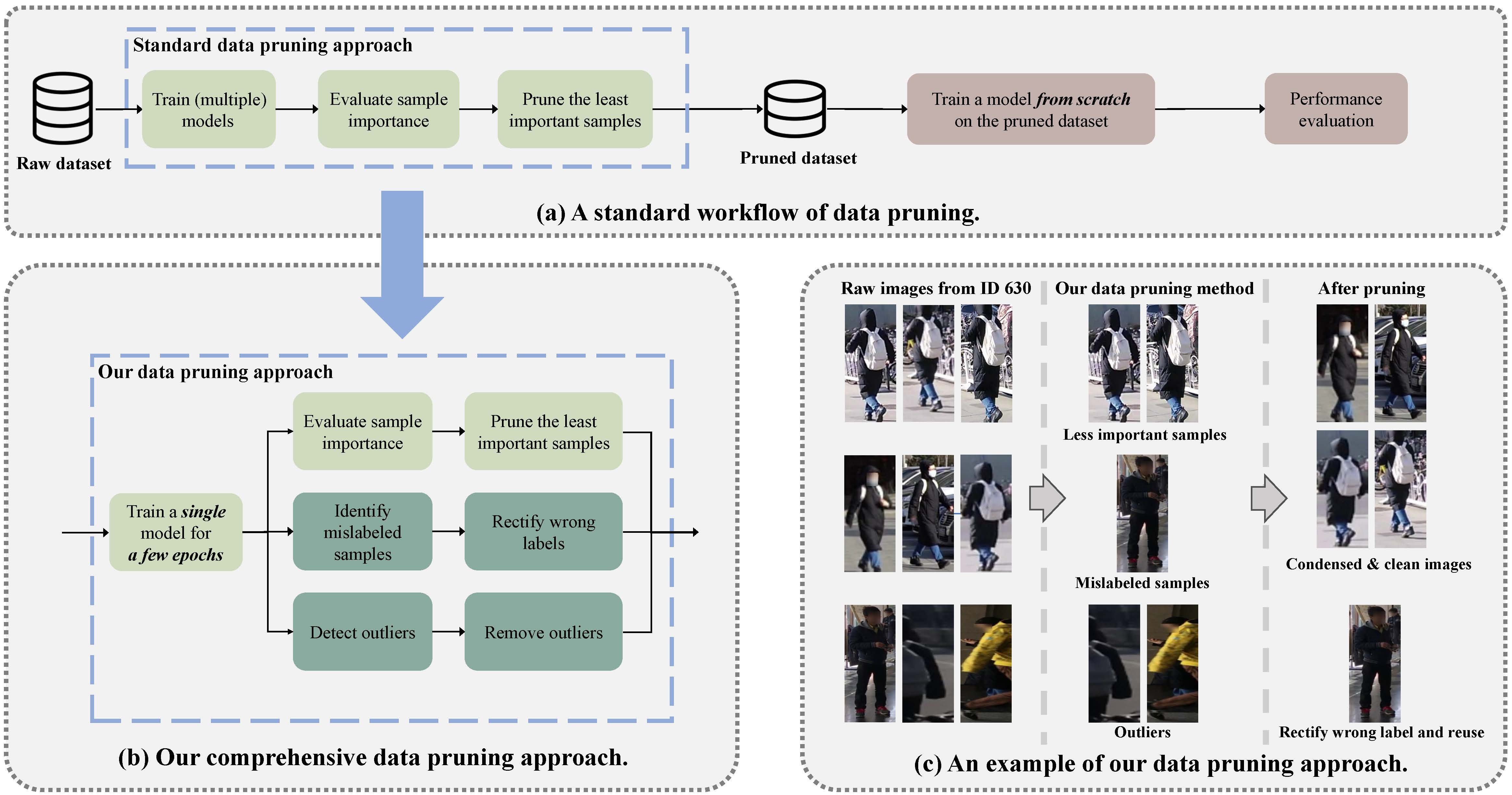
- Figure 1: The workflow of data pruning. Our data pruning approach not only identifies less important samples, but also rectifies mislabeled samples and removes outliers (boxes highlighted in turquoise). Figure (c) demonstrates an example of our method, where all images are from the same person (id 630, MSMT17 dataset). Our approach serves as a pre-processing step, reducing the dataset size to save storage and training costs of ReID models while having minimal impact on their accuracy.
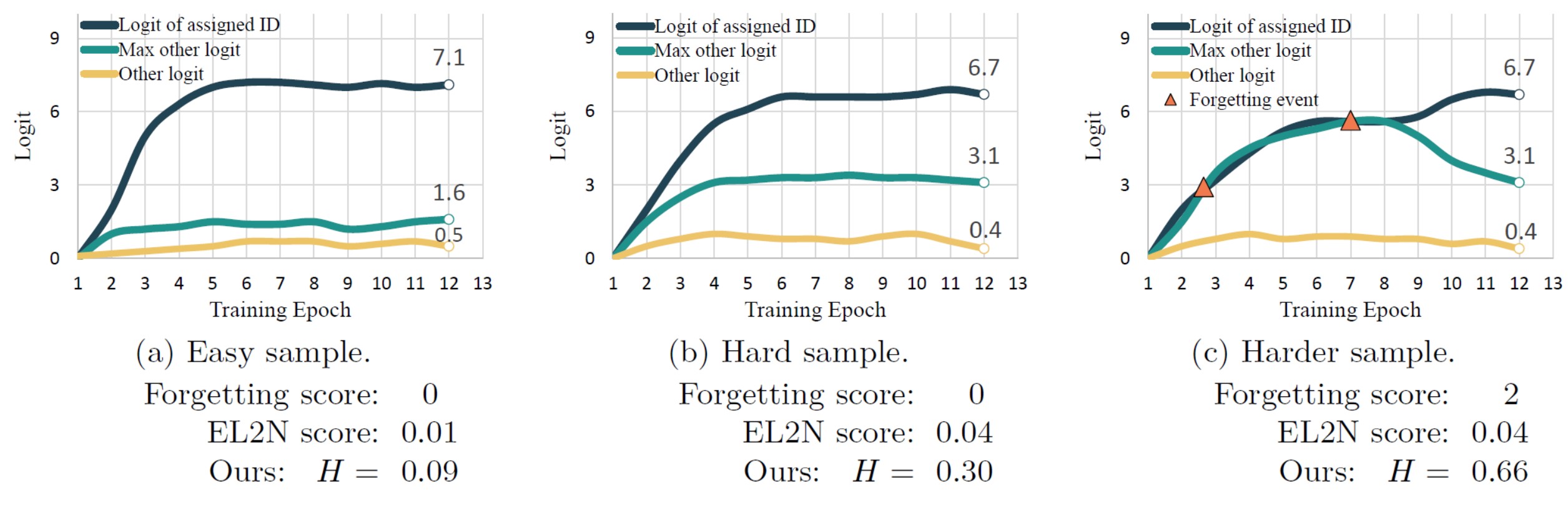
- Figure 2: Logit trajectories for three samples (i.e., the evolution of the log probabilities of each sample belonging to each class over the course of training): (a) easy sample, (b) hard sample and (c) harder sample. There are three classes in total and each logit trajectory corresponds to one of such classes. The difference between the logits for each class can reflect the level of difficulty of this sample. In general, the more difficult the sample, the more important it is. The forgetting scores cannot distinguish (a) and (b), while the EL2N score relies solely on the model’s prediction at the last epoch (thus without considering the history or “training dynamics”), hence it cannot differentiate between (b) and (c). Our approach fully exploits the training dynamics of a sample by utilizing the average logits values over all epochs to generate a more robust soft label. Then, the entropy of this soft label is employed to summarize the importance of a sample.
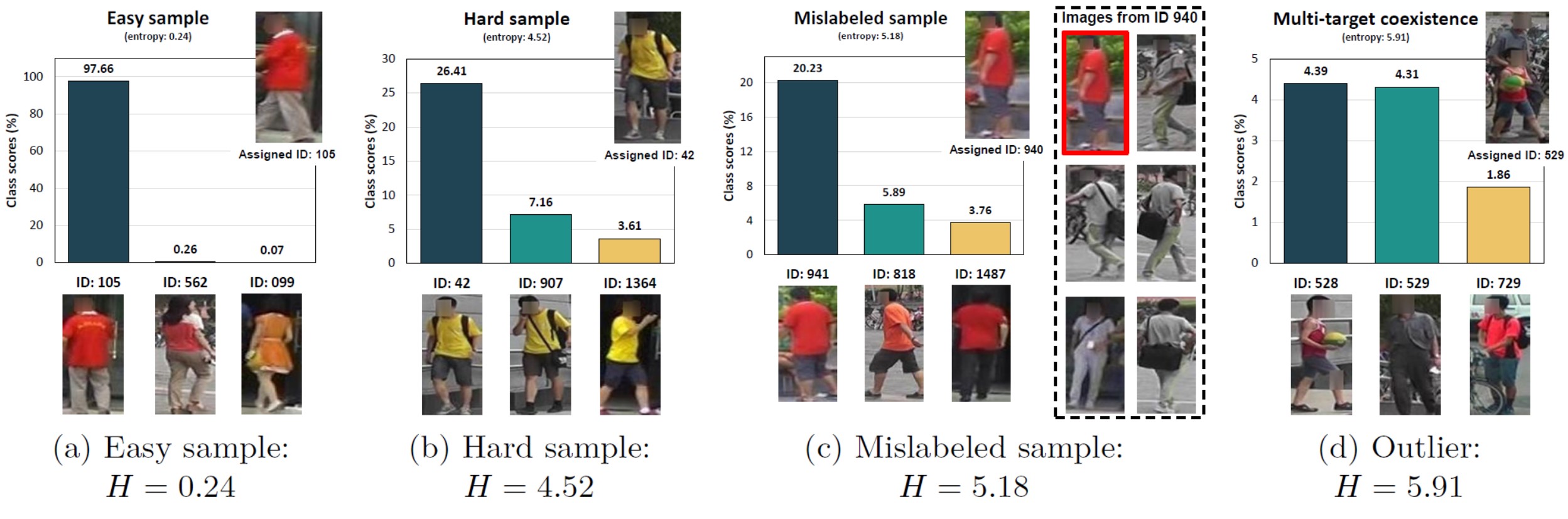
- Figure 3: Illustration of the generated soft labels averaged over 12 training epochs for different sample types (a)–(d) and their entropies. Multi-target coexistence (d) is one such type of outlier. We show the top 3 identities. Notably, our soft label can accurately indicate the ground-truth label of the mislabeled sample (c) without being influenced by the erroneous label. Images are from Market1501 dataset.
All lists are saved in ./ReID_sample_lists. All lists will be available soon!
There are three folders, each corresponding to a ReID dataset, i.e., Marker1501, MSMT17 and VeRi. Below is a description of each folder:
- Contents:
fpath_list.npy: This npy file contains the file name of each sample and it can be used to map file name to indexRanking_list: This npy file contains the file names of samples sorted by our importance scores (from the most difficult to the simplest).Mislabeled_outlier_samples.pickle: This pickle file is a dictionary containing two numpy arrays:- The first numpy array is 2-dimensional and contains the predicted person ID for each sample based on our generated soft labels. The first column represents the index of each sample, and the second column represents the predicted person ID.
- The second numpy array is 1-dimensional and contains the indices of outlier samples.
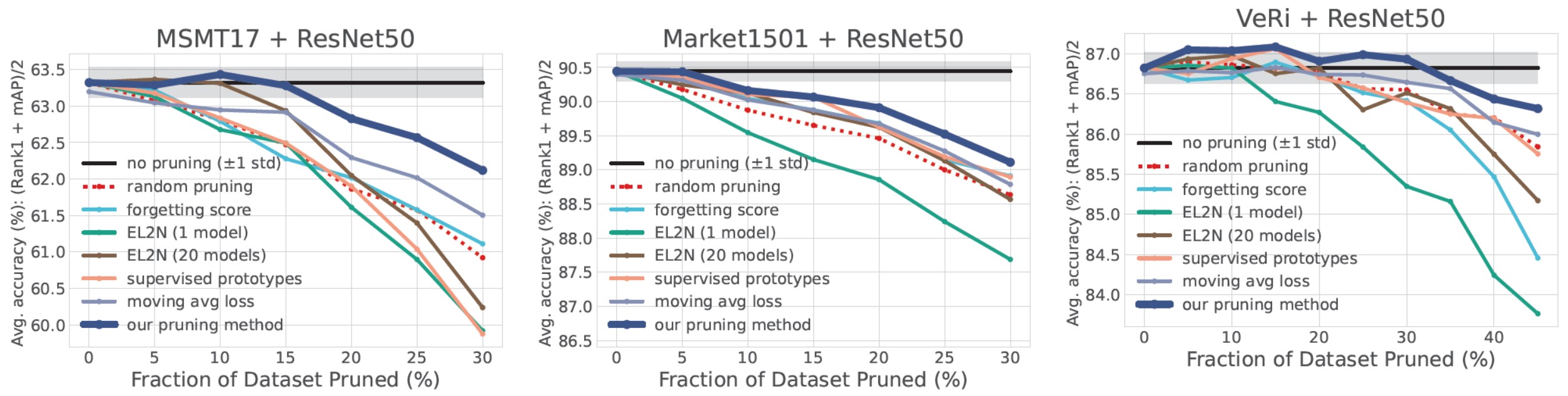
- Figure 4: Data pruning on ReID datasets. We report the mean of Rank1 and mAP on 3 ReID datasets (labeled at the top), obtained by training on the pruned datasets. For each method, we carry out four independent runs with different random seeds and report the mean.
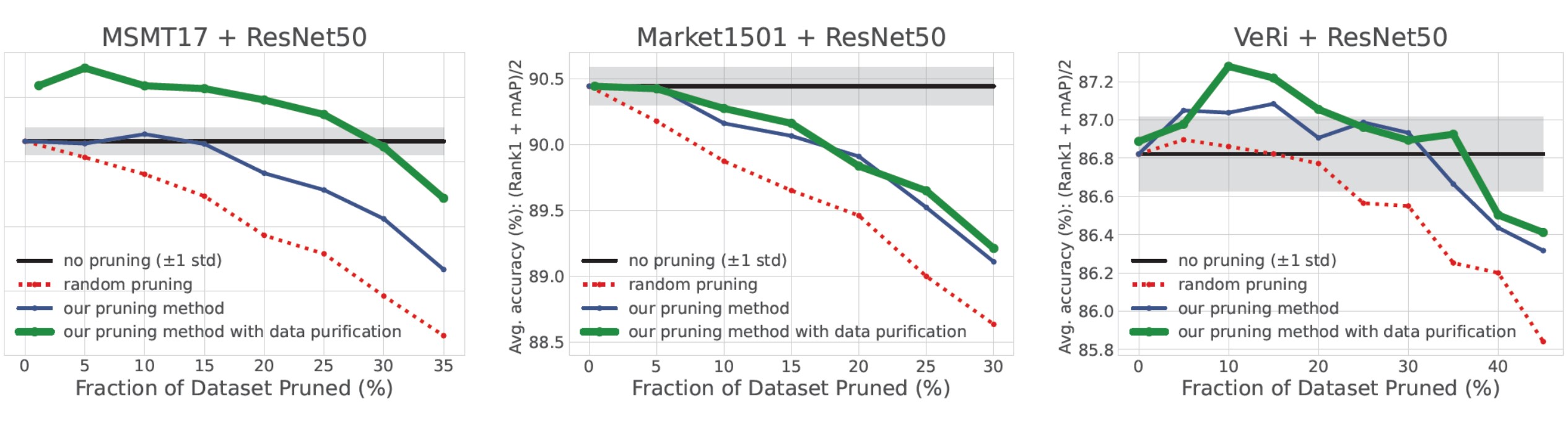
- Figure 5: Data pruning with data purification. Accuracy is achieved by training on the pruned dataset (pruning ratios on X-axis). We report the mean values from four independent runs with different seeds.
If you find our work useful for your research, please cite our paper as follows:
@article{
yang2024data,
title={Data Pruning Can Do More: A Comprehensive Data Pruning Approach for Object Re-identification},
author={Zi Yang and Haojin Yang and Soumajit Majumder and Jorge Cardoso and Guillermo Gallego},
journal={Transactions on Machine Learning Research},
issn={2835-8856},
year={2024},
url={https://openreview.net/forum?id=vxxi7xzzn7},
note={}
}