Features Walkthrough
To understand all features, please first familiarize yourself with the Arrows and Nodes Model the framework is based on.
All examples can be run by saving the specification to a .yf file in a directory and executing Scraper in that directory (e.g. docker run -v "$PWD":/rt/ --rm albsch/scraper:latest).
A taskflow can be written in both JSON (file ending .jf) and YML (file ending .yf).
name: helloworld
# entry: start
# globalNodeConfigurations: {}
# imports: {}
graphs:
start:
- type: EchoNode
log: "Hello world!"
- type: EchoNode
log: "I accept the output of the previous node!"
- type: EchoNode
log: "I'm the last node in the graph!"
other:
- type: EchoNode
log: "I'm not reachable and not used :("Mandatory:
-
name: Identifier for the taskflow specification -
graphs: A map where keys are identifiers a single graph. Values are lists of nodes.
Optional:
-
entry: Which graph is going to be used for the first entry task on startup. Default value isstart. -
globalNodeConfigurations: Used to configure multiple nodes at once. Local node configuration has precedence over global node configuration. Default is no global node configurations. See the Global Node Configuration section. -
imports: Used to import other taskflows into this taskflow. See the Importing Other Taskflows section.
Each node in a graph can be configured depending on its implementation. A node is a key-value map in the specification. The documentation for each configuration of the core and dev Scraper nodes can be found here. The documentation (for your own nodes) can be generated, for more information see the Generating Node Documentation section of the developer guide.
Example: EchoNode creating a static output at key obj (EchoNode Documentation):
- type: EchoNode
log: "Creating object"
put: obj:
value:
id: 10
name: smith
age: 20The types of the node configuration has to match the types defined in the node implementation, which can be checked with the generated documentation:
-
put: Where to put the object generated byvalue -
value: The object to put at theputlocation of typeA
Failing to match the types will throw an exception on starting the taskflow.
If a node is extending another node implementation, then it inherits the configuration of its parent. Generally, every node has a basic node configuration provided by Node.
Every node by default forwards to the next node using a dependent arrow.
The next target can be configured via the configuration keys forward and goTo (Node Documentation) where next is defined as follows:
- If
forwardisfalse, then do not forward - If
goTois not set, then forward to the following node in the graph (list) this node is in- If this node is the last node in the graph, then do not forward
- If
goTois set, then resolve the address and forward to that target address (see Address Schema)
If the node implementation does not create other dependent arrows (i.e. modifying control flow), then not forwarding is the same as the flow terminating.
name: goto
graphs:
start:
- type: EchoNode
goTo: other
- type: EchoNode
log: "I'm a labelled node!"
label: anecho
- type: EchoNode
log: "I'm the last node in the graph!"
other:
- type: EchoNode
log: "A short detour to another graph"
goTo: start.anecho
- type: EchoNode
log: "I'm not reachable :("
It is usually enough and recommended to only address up to graph labels and not address single nodes directly.
A flow map is a key-value map and travels along arrows.
For a dispatched arrow the flow map is copied for the newly created flow.
If multiple dependent arrows originate from the same node, then the node implementation decides which order the flow map is forwarded in.
This is usually marked in the generated control flow graph.
Flow maps are used to carry data around and for dynamic node configuration dependent on the currently accessing flow map via templates.
name: echotest
graphs:
start:
- type: PipeNode
pipeTargets: [ok, ok2]
# continue with the pipe result
- type: EchoNode
log: "My flow map contains both ok and ok2!"
ok:
- type: EchoNode
put: ok # fills key ok in the accepting flow map
value: hello
ok2:
- type: EchoNode
put: ok2 # fills key ok2 in the accepting flow map
value: hello
Nodes used: EchoNode and PipeNode.
This example has no observable behavior. To inspect and use the contents of the flow map, templates can be used.
To use flow map content and to make the configuration of nodes dependent on input, templates are used. A templating engine is embedded into Strings and follows a simple grammar.
-
{X}: Value of flow map at keyX -
{X}[Y]: List element at indexYof listX. It follows thatXhas to be a nested template which has to evaluate to a list andYan Integer (or template that evaluates to an Integer) -
{X@Y}: Map element at keyYof mapX. It follows thatXhas to be a nested template which has to evaluate to a map andYa String (or template that evaluates to an String) -
{X}{Y}: String concatenation -
helloworld: Static template
name: echoinspect
graphs:
start:
- type: PipeNode
pipeTargets: [ok, ok2]
- type: EchoNode
log: # print out a map
info: "My input contains a list at oklist and a map at okmap"
# {oklist} resolves to the list, {_}[0] inspects the content
msg1: "{{oklist}}[0] {{oklist}}[1]"
msg2: "{okmap}"
msg3: "Is {{okmap}@age} years old"
# use JSON embedding to save a bit of space
ok: [ {type: EchoNode, put: oklist, value: [hello, world] } ]
# age: 25 does not work, as it is an integer and not a String
# using 25 causes the typechecker to throw an error, prohibiting the execution of the workflow
ok2: [ {type: EchoNode, put: okmap, value: {name: smith, age: "25"} } ]For the log configuration of Node we use the fact that it has the type T<?>.
This means String templates can be inside lists and maps, too.
Every nested template is evaluted.
This mechanism makes a simple EchoNode quite powerful, as it allows the user to build custom JSON objects to use or store.
Assume that in the taskflow before you gathered an id, a list of String comments at comments and a String title at title. To save a JSON document to disk, you first have to build it, EchoNode can be used for this purpose:
name: staticoutput
graphs:
start:
- type: EchoNode # replace this EchoNode with another taskflow that gathers information
puts: {id: 1, title: "hello world", comments: ["lorem", "ipsum"] }
- type: EchoNode
puts:
jsondoc:
id: "{id}"
title: "{title}"
comments: "{comments}" # a list!
new: true # some static information
- type: ObjectToJsonStringNode
object: "{jsondoc}"
#result: "result"
- type: WriteLineToFileNode
output: "out.json"
line: "{result}"
overwrite: true
Nodes used: EchoNode, ObjectToJsonStringNode, WriteLineToFileNode
The absolute address schema is
taskflow.graph.label or taskflow.graph.index.
Relative address schemas are allowed.
addr as seen from a node can be (checked in this order):
- local node with label
addr - graph id
addr - imported taskflow
addr
addr1.addr2 as seen from a node can be (checked in this order):
- node
addr2 in graphaddr1` - graph
addr2in imported taskflowaddr1
name: myflow
graphs:
start:
- type: PipeNode
pipeTargets: ["localnode", "localgraph", "graph.nodeingraph", "myflow.graph.0"]
- { type: EchoNode, log: "Finished!", forward: false }
- { type: EchoNode, log: "I'm addressed directly", label: localnode }
localgraph:
- { type: EchoNode, log: "localgraph!" }
graph:
- { type: EchoNode, log: "first node in graph!" }
- { type: EchoNode, log: "I'm accessed twice!", label: nodeingraph }
Addressing nodes inside graphs could make the resulting control flow less understandable:
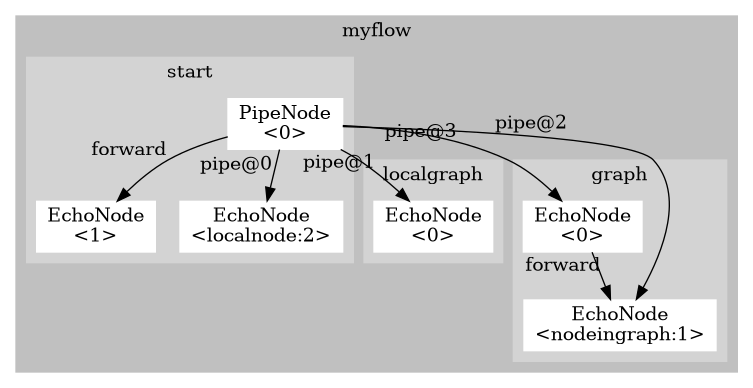
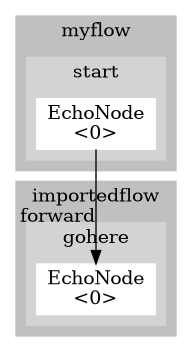
Importing is used to modularize the taskflow. The addressing can only happen from parent to child: nodes in a child taskflow cannot address nodes in a parent task flow.
The design of importing taskflows is under discussion and feedback is welcome.
Currently, imports is a map where the key specifies the path of the taskflow to import and the value is unused.
myflow.yf:
name: myflow
imports:
import.yf:
graphs:
start:
- { type: EchoNode, log: hello, goTo: importedflow.gohere }
import.yf:
name: importedflow
graphs:
gohere:
- { type: EchoNode, log: "I'm here now" }
When using more than one specification, the main specification has to be supplied as a command line argument,
e.g. docker run -v "$PWD":/rt/ --rm albsch/scraper:latest myflow.yf.
The core framework is able to generate flow graphs to visualize the specification via the nodes and arrows model.
root.yf:
name: root
imports:
child.yf:
graphs:
start:
- { type: EchoNode, log: "Starting taskflow"}
- { type: PipeNode, pipeTargets: [arg1, root.arg2.0] }
- { type: EchoNode, log: "Finished: {arg1} {arg2}!"}
arg1:
- { type: EchoNode, puts: {elements: ["1","2","4","5","6"]} }
- { type: MapNode, list: "{elements}", mapTarget: child.api, putElement: a }
- { type: EchoNode, puts: {arg1: hello}}
arg2:
- { type: EchoNode }
- { type: EchoNode, puts: {elements: ["wo", "rl", "d"]} }
- { type: MapNode, list: "{elements}", mapTarget: child.api, putElement: a }
- { type: EchoNode, puts: {arg2: "{{elements}}[0]"} }
child.yf:
name: child
graphs:
# API
# a :: String
api:
- { type: EchoNode, log: "Got input {a}"}
Executing cfg will yield (e.g. docker run -v "$PWD":/rt/ --rm albsch/scraper:latest root.yf cfg exit)
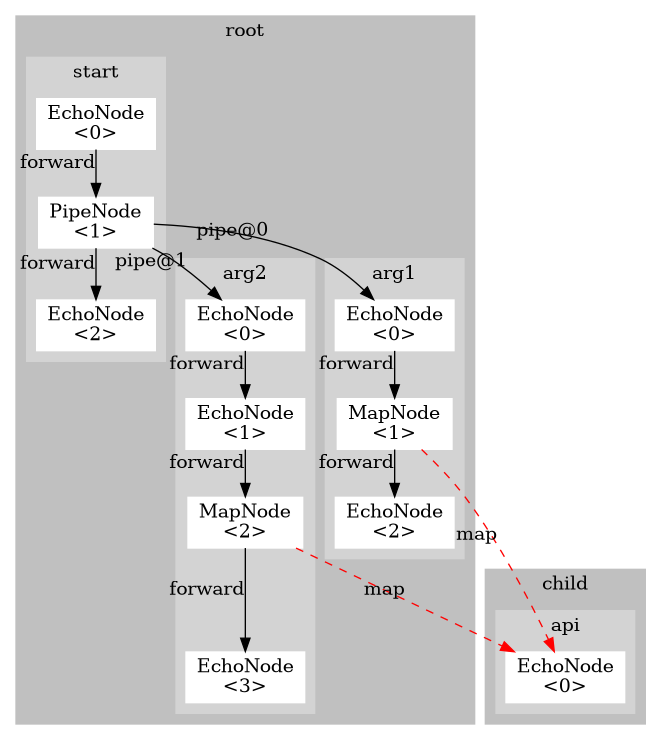
Currently, crossed arrows are depicted as red arrows in the flow graph generator.
Global node configurations can be specified by node type or regex match on node types.
Regex have to be surrounded by //.
name: myflow
globalNodeConfigurations:
EchoNode:
log: "Global logging"
"/Pipe.*/":
log: "My target is tar"
pipeTargets: [tar]
graphs:
start:
- { type: EchoNode, log: "hello"}
- { type: PipeNode }
tar:
- { type: EchoNode }
To compile custom nodes, the need to be in the top level scraper Java package. The api and annotations jar is needed to compile.
Example:
package scraper;
import scraper.annotations.NotNull;
import scraper.annotations.node.*;
import scraper.api.flow.FlowMap;
import scraper.api.node.container.*;
import scraper.api.node.type.FunctionalNode;
import scraper.api.template.T;
@NodePlugin("1.0.0")
public class MyNode implements FunctionalNode {
@FlowKey(defaultValue = "\"default\"") private T<String> config = new T<>(){};
@Override public void modify(FunctionalNodeContainer n, FlowMap o) {
String x = o.eval(config);
n.log(NodeLogLevel.ERROR, "Hello, {}!", x);
}
}Save as MyNode.java.
The docker image provides an easy way to include custom nodes:
name: myflow
graphs:
start:
- { type: MyNode, config: "hello !"}
Place custom nodes in nodes and they will be compiled and provided to Scraper.
docker run -v "$PWD":/rt/ -v "$PWD/nodes":/custom/ --rm albsch/scraper:latest
For more information on node implementation features, read the node developer guide.
For complex nodes with dependencies, include them as fully built jars instead, by putting them in the /nodes folder or provide them for the runnable jar:
docker run -v "$PWD":/rt/ -v "$PWD":/nodes/ --rm albsch/scraper:latest
If you assume your node jars and the runnable Scraper jar reside in the same folder:
java -cp "*" scraper.app.Scraper