Identifying file formats
Siegfried is a command line tool. If you aren't a frequent user of command prompts, it may be helpful to start by reading one of these guides: Windows, OSX or Linux
Scanning a file with siegfried just involves navigating to the right directory (using the cd command) and running:
sf file.ext
You can scan the whole contents of directories by providing a directory rather than a file as the first argument:
sf DIR
By default, siegfried will descend down into all the subdirectories of that directory. You may not want this (especially if it is a large directory) and can prevent it with a -nr flag (for "no recurse") like so:
sf -nr DIR
Tip: Because
sfis run from the command line, you can use the standardctrl-Ckey combination to kill the command if you accidentally start descending down a really big directory tree.
Siegfried's output has been designed to print nicely in terminals but oftentimes you'll want to keep the scan results. To do this, simply redirect (>) the output to a results file:
sf file.ext or DIR > my_results.yaml
I gave my_results a .yaml extension because the default output format is YAML. You can switch the output to JSON, CSV or DROID CSV with the -json, -csv and -droid flags:
sf -json DIR > my_results.json
sf -csv DIR > my_results.csv
sf -droid DIR > my_results.csv
By default, siegfried does not scan within archive formats. To scan within the contents of zip, tar, gzip, warc or arc files use the -z flag:
sf -z file.ext
sf -z DIR
To include file hashes with your identification results, use the -hash flag:
sf -hash md5 file.ext
sf -hash sha1 DIR
If you give - instead of a file or directory argument, sf will read a list of files from stdin. This allows you to do things like:
find */*.doc | sf - [on Mac or Linux]
dir /b /s *.doc | sf - [on Win]
If you use the throttle [Duration] flag, sf will pause between files when scanning directories. For example:
sf -throttle 50ms DIR
will pause for 50 milliseconds between each file. This flag can be useful if you encounter bandwidth issues running sf.
If you forget a command or option, use sf -help for a list of options.
The -log flag reports progress, errors, warnings, knowns, unknowns, and slow and debug information to either stderr or stdout.
For example, if you're scanning a large directory, you might like to see the progress of your scan. You can do this with -log progress:
sf -log progress -csv DIR > my_results.csv
This command reports progress to stderr (the default output).
The -log flag takes the following options:
progress OR p
error OR err OR e
warning OR warn OR w
known OR k
unknown OR u
debug OR d
slow OR s
stdout OR out OR o
You can combine any of these options in comma-separated strings e.g. -log e,w will report all errors and warnings to stderr. -log u,o will report all unknowns to stdout (when you direct -log to stdout it takes the place of the normal result output).
The -log known and -log unknown commands output lists of files that are either recognised or not recognised.
One use for these commands is in combination with a modified signature file (see Building a signature file with roy). For example, you could create a signature file that only recognises pdf formats with:
roy build -limit @pdf -name pdf_only pdf.sig
Using sf -log known you could then filter all the pdf files in a given directory for further processing by some other command, such as tika:
sf -sig pdf.sig -log known,stdout . > temp.out && java -jar tika-app.jar -t -i . -o ~/local/out -fileList temp.out
Or you might want to send a list of unknowns to the file command:
sf -log unknown ~/local/files 2> temp.out && file -f temp.out
You can even pipe results from these commands back to sf itself. For example, you might run a full identification over all the non-pdf files in a directory:
sf -sig pdf.sig -log unknown,stdout . | sf -
Note: the JSON and CSV outputs have identical fields to the YAML output, except that the CSV output omits the technical provenance block. The DROID output mimics the TNA's DROID tool's CSV export.
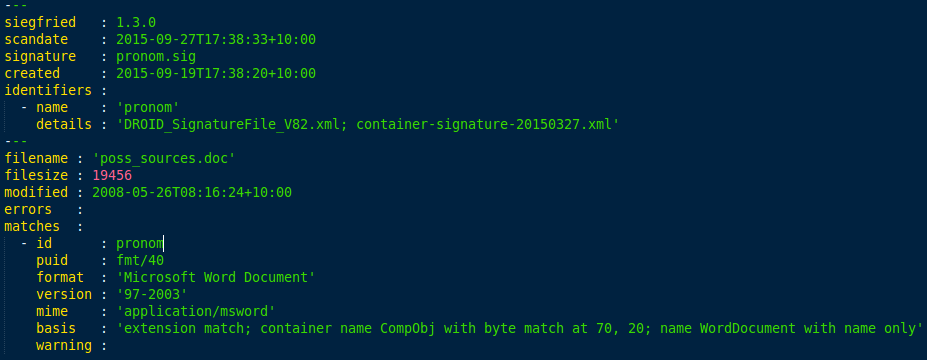
The first block of information in siegfried output gives a technical provenance for the scan.
This includes information about siegfried (version number), about the date and time of the scan, about the signature file (name and date created), and about the identifiers within that signature file. The default signature file (pronom.sig) includes a single identifier named "pronom". In the "details" field for an identifier you'll see the versions of DROID signature files used to create the identifier as well as any modifications made to it (e.g. limited BOF, extensions etc.). No modifications are made to the default signature file's PRONOM identifier.
The second block of information in siegfried ouput describes the file being scanned.
This includes the file's name, size (in bytes), last modified date, and any errors siegfried encountered in attempting to read the file. Treat any errors reported here as red flags warranting further investigation. File errors may prevent matching occurring altogether or they may only affect certain matching processes. For example, a badly structured zip or Microsoft Compound file will prevent prevent container matching and generate a file error but the byte matcher will still report its results.
The third block of information in siegfried output is a list of matches reported by the identifiers within the signature file. All identifiers will return at least one match (which may have the special value "UNKNOWN") and may report multiple matches (if there are multiple matches returned that have equal weighting).
For each match you will see:
- the name of the identifier returning the match (just "pronom" if you are using the default signature file)
- the puid (a unique PRONOM identifier or the special value "UNKNOWN")
- the format's name, version and MIME type
- the basis for the match
- and any warnings.
The basis field gives a technical justification for why the format has matched. This includes the names of the matchers (extension, container, byte and text matchers) that have triggered the result. If it is a byte matcher result, you will also see comma separated pairs that describe the offsets and lengths of matching segments (signatures may have one or more segments that must be satisfied). If it is a container matcher, you will see the names of matching sub-files as well as the output of any byte matchers that are applied to those sub-files. If it is a text matcher, you will see the character encoding detected.
For example:
'extension match; container name CompObj with byte match at 77, 20; name WordDocument with name only'
This basis value tells us that file in question matched on extension and triggered a container match, due to the sub-files "CompObj" and "WordDocument", with a byte match for the "CompObj" stream.
The warning field reports any warnings reported by the identifiers during matching. These aren't strictly errors but may still warrant further investigation. A common warning is for "UNKNOWN" files. The warning text for "UNKNOWN" files will list any potential matches based on extension that the byte matcher has excluded.