Shouldn't FP16 = True give faster transcription time ? #622
Replies: 3 comments
-
|
I also observe that there is no real improvement when using FP16 on a V100. So I suspect something is missing for the "real" support of precision float16. In details, what I see is:
Here is a graph showing this:
So only for beam search decoding with large model I saw an improvement with fp16=True. Which is maybe not even significant... |
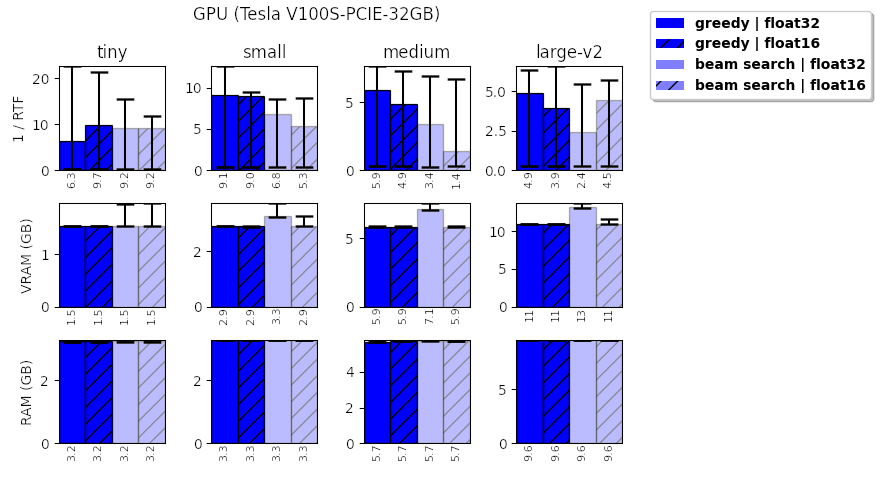
Beta Was this translation helpful? Give feedback.
-
|
Oh, and I tried to convert the model to fp16 but then the decoding just fails when I call |
Beta Was this translation helpful? Give feedback.
-
|
exactly, i asked a question #1175 but no answer |
Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
-
Hi,
I am surprised because I would expect (see Nvidia explanations) that running transcribe with half precision (see
transcribe(..., fp16=True)) would run faster than with normal precision (default parameter), but the contrary happens.I did the experiment on an RTX 3090 with the large model and got around 45 s with default parameter (fp16=False so fp32) but got respectively 135 and 104 s with half precision mode.
Is this what was expected or it comes from the old cpu architecture that cannot cope with higher throughput ?
Thanks in advance for any hint !
Beta Was this translation helpful? Give feedback.
All reactions